What is Qwen3-TTS?
Qwen3-TTS is a series of powerful speech generation models developed by Qwen, offering comprehensive support for voice clone, voice design, ultra-high-quality human-like speech generation, and natural language-based voice control. It provides developers and users with the most extensive set of speech generation features available. The models cover 10 major languages (Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, and Italian) as well as multiple dialectal voice profiles to meet global application needs.Key Features
Powerful Speech Representation
Powered by the self-developed Qwen3-TTS-Tokenizer-12Hz, it achieves efficient acoustic compression and high-dimensional semantic modeling of speech signals. It fully preserves paralinguistic information and acoustic environmental features, enabling high-speed, high-fidelity speech reconstruction through a lightweight non-DiT architecture.
Universal End-to-End Architecture
Utilizing a discrete multi-codebook LM architecture, it realizes full-information end-to-end speech modeling. This completely bypasses the information bottlenecks and cascading errors inherent in traditional LM+DiT schemes, significantly enhancing the model’s versatility, generation efficiency, and performance ceiling.
Extreme Low-Latency Streaming
Based on the innovative Dual-Track hybrid streaming generation architecture, a single model supports both streaming and non-streaming generation. It can output the first audio packet immediately after a single character is input, with end-to-end synthesis latency as low as 97ms, meeting the rigorous demands of real-time interactive scenarios.
Intelligent Voice Control
Supports speech generation driven by natural language instructions, allowing for flexible control over multi-dimensional acoustic attributes such as timbre, emotion, and prosody. By deeply integrating text semantic understanding, the model adaptively adjusts tone, rhythm, and emotional expression, achieving lifelike “what you imagine is what you hear” output.
Model Architecture
Qwen3-TTS employs a discrete multi-codebook language model architecture for end-to-end speech generation: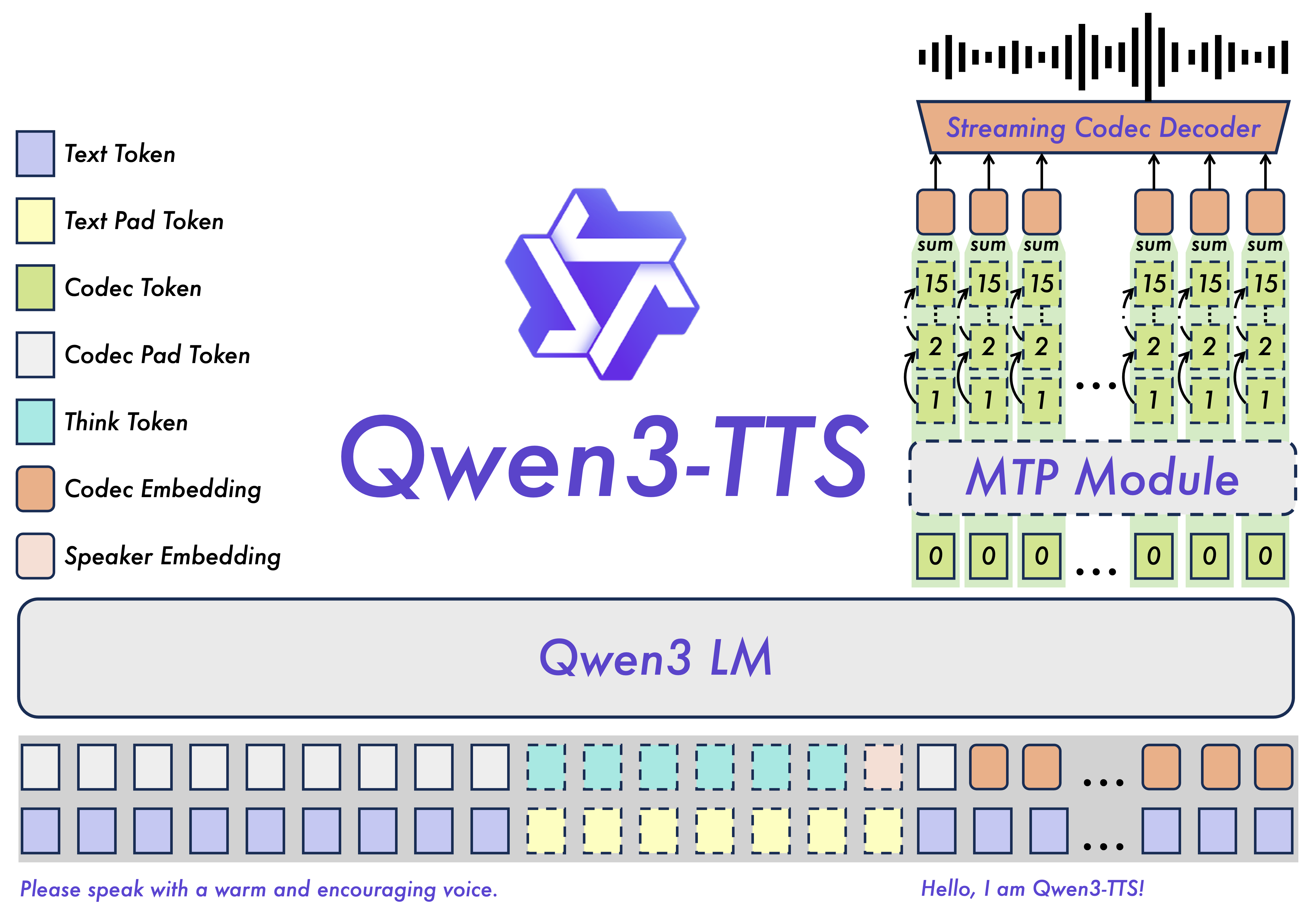
- Qwen3-TTS-Tokenizer-12Hz: Encodes speech into discrete codes and decodes them back
- Language Model: Generates speech codes conditioned on text and optional prompts
- Dual-Track Generation: Supports both streaming and non-streaming modes
Released Models
Below is an overview of the Qwen3-TTS models currently available:Tokenizer
| Model Name | Description |
|---|---|
| Qwen3-TTS-Tokenizer-12Hz | The tokenizer model that encodes input speech into codes and decodes them back into speech |
TTS Models
| Model | Size | Features | Languages | Streaming | Instruction Control |
|---|---|---|---|---|---|
| Qwen3-TTS-12Hz-1.7B-VoiceDesign | 1.7B | Voice design based on user-provided descriptions | 10 languages | ✅ | ✅ |
| Qwen3-TTS-12Hz-1.7B-CustomVoice | 1.7B | Style control over 9 premium timbres via user instructions | 10 languages | ✅ | ✅ |
| Qwen3-TTS-12Hz-1.7B-Base | 1.7B | 3-second rapid voice clone; can be fine-tuned | 10 languages | ✅ | — |
| Qwen3-TTS-12Hz-0.6B-CustomVoice | 0.6B | Supports 9 premium timbres | 10 languages | ✅ | — |
| Qwen3-TTS-12Hz-0.6B-Base | 0.6B | 3-second rapid voice clone; can be fine-tuned | 10 languages | ✅ | — |
All models support Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, and Italian.
Model Selection Guide
CustomVoice Models
CustomVoice Models
Choose these models when you want to use predefined premium timbres with optional instruction-based style control. The 1.7B variant supports natural language instructions to control tone, emotion, and prosody.Use cases: Professional content creation, audiobooks, consistent character voices
VoiceDesign Model
VoiceDesign Model
Choose this model when you want to create custom voices from natural language descriptions. Describe the desired voice characteristics (age, gender, tone, emotion) and the model will generate matching speech.Use cases: Character design, creative projects, personalized voice synthesis
Base Models
Base Models
Choose these models when you need voice cloning from a 3-second audio sample, or when you want to fine-tune the model for specialized domains.Use cases: Voice cloning, custom speaker adaptation, fine-tuning for specific applications
Next Steps
Installation
Set up your environment and install Qwen3-TTS
Quickstart
Generate your first speech with Qwen3-TTS