
Welcome to Omnilingual ASR
Omnilingual ASR is an open-source speech recognition system supporting over 1,600 languages — including hundreds never previously covered by any ASR technology. Designed for broad accessibility, it enables new languages to be added with just a few paired examples without requiring specialized expertise or large datasets. By combining scalable zero-shot learning with a flexible model family, Omnilingual ASR aims to make speech technology more inclusive and adaptable for communities and researchers worldwide.Quick Start
Get transcribing audio in minutes with simple Python code
Installation
Install via pip or uv and set up your environment
Supported Languages
Explore 1600+ languages with language ID format reference
Model Architecture
Learn about W2V, CTC, and LLM model families
Key Features
1600+ Language Support
1600+ Language Support
State-of-the-art performance across 1,600+ languages with character error rates (CER) below 10% for 78% of those languages. Includes hundreds of languages never previously covered by ASR technology.
Multiple Model Families
Multiple Model Families
Choose from three model architectures:
- CTC Models: Fast parallel generation (up to 96x real-time)
- LLM Models: Language-conditioned transcription with optional context
- Zero-Shot Models: Transcribe new languages with just a few examples
Flexible Model Sizes
Flexible Model Sizes
Available in 300M, 1B, 3B, and 7B parameter variants to balance accuracy and computational resources.
Zero-Shot Learning
Zero-Shot Learning
Add support for new languages with just a few paired audio-text examples using the zero-shot model variant.
Performance Highlights
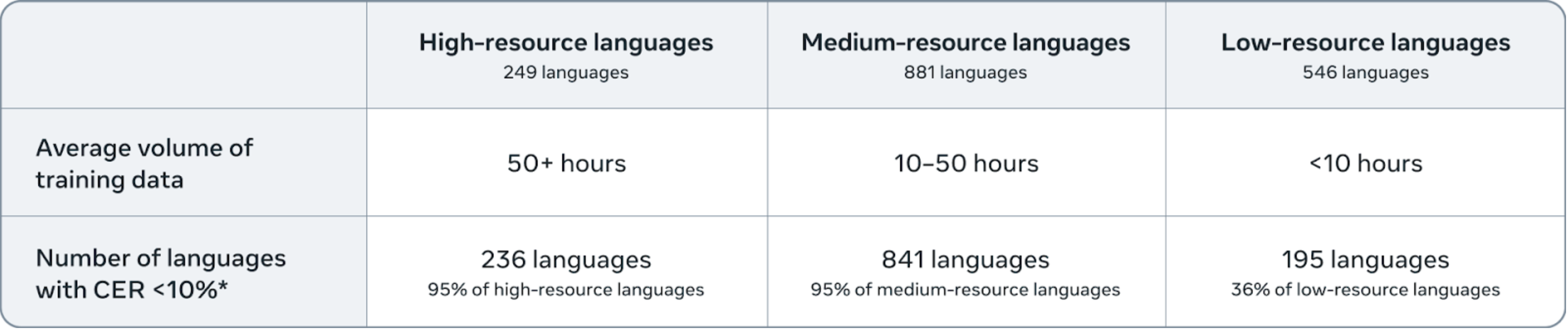 Our 7B-LLM-ASR system achieves state-of-the-art performance across 1,600+ languages, with character error rates (CER) below 10 for 78% of those languages.
Our 7B-LLM-ASR system achieves state-of-the-art performance across 1,600+ languages, with character error rates (CER) below 10 for 78% of those languages.
Model Architecture Overview
Omnilingual ASR provides three distinct model families:SSL (Self-Supervised Learning) Models
Pre-trained wav2vec2 encoders that learn speech representations without transcriptions. These serve as the foundation for both CTC and LLM models.CTC (Connectionist Temporal Classification) Models
Fast, parallel transcription models ideal for real-time applications:- Real-Time Factor: 0.001-0.006 (16x to 96x faster than real-time)
- Use Case: High-throughput batch processing
- Limitation: No language conditioning support
LLM (Language Model) Models
Autoregressive models with optional language conditioning:- Real-Time Factor: ~0.09 (approximately real-time)
- Language Conditioning: Specify target language for better accuracy
- Unlimited Variants: Support for audio of any length
- Zero-Shot Variant: Learn new languages from context examples
December 2025 Update
We released two major improvements:- Improved v2 Models: Enhanced accuracy (CER) for both CTC and LLM-ASR models
- Unlimited Audio Length: New LLM variant supporting transcription of unlimited-length audio (
omniASR_LLM_Unlimited_{300M,1B,3B,7B}_v2)
Resources
Research Paper
Read the full technical paper
Blog Post
Learn about the research and development
HuggingFace Demo
Try the interactive demo
Dataset
Access the multilingual corpus
Next Steps
Install the Package
Follow the installation guide to set up Omnilingual ASR in your environment.
Run Your First Transcription
Try the quick start guide to transcribe your first audio file.
Explore Advanced Features
Learn about language conditioning and zero-shot learning.