
Why HiCache?
In large language model inference, the prefill phase is often time-consuming: input sequences must first be converted into Key-Value cache (KV cache) for subsequent decoding. When multiple requests share the same prefix, the KV cache for that prefix is identical. By caching and reusing these shared KV caches, redundant computation can be avoided. SGLang’s RadixAttention leverages idle GPU memory to cache and reuse prefix KV caches. HiCache extends this idea to host memory and distributed storage, inspired by the classic three-level cache design of modern CPUs:- L1 Cache: GPU memory (fast, private per instance)
- L2 Cache: Host memory (larger capacity, private per instance)
- L3 Cache: Distributed storage (shared across cluster)
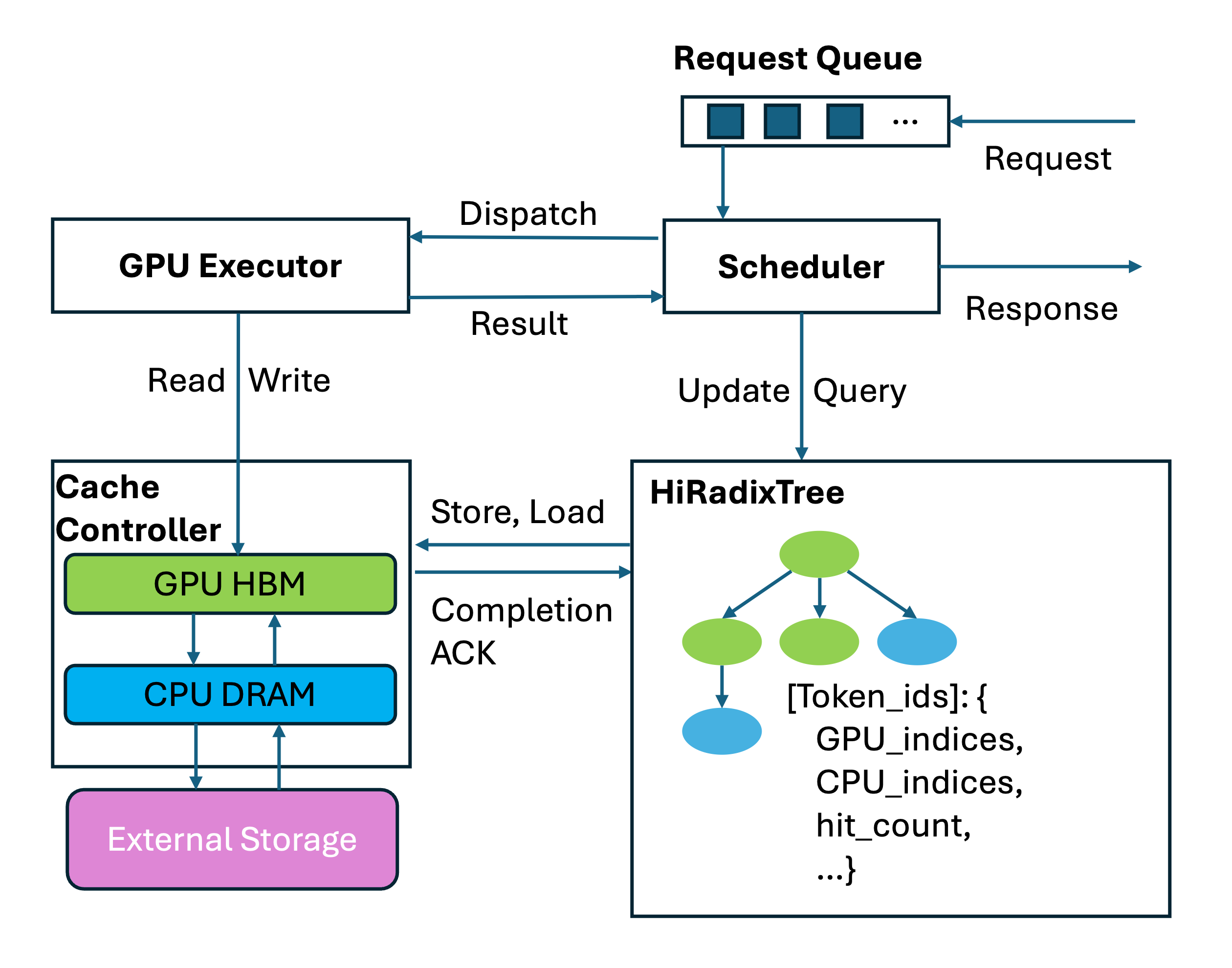
System Architecture
HiRadixTree: Metadata Organization
HiCache builds upon the RadixTree structure introduced in RadixAttention. In RadixAttention, each node of the RadixTree corresponds to the KV cache of a consecutive span of tokens in GPU memory. HiRadixTree extends this:- Each node corresponds to the KV cache of a span of consecutive tokens
- Records where that KV cache is stored (L1 GPU memory, L2 CPU memory, L3 storage, or multiple tiers)
- For local storage (L1/L2), maintains precise metadata including exact storage addresses
- For L3 storage, queries the backend in real time to retrieve metadata on demand
Three-Phase Workflow
HiCache operates through three key phases:1. Local Match
When a new request arrives, HiCache first searches local L1 and L2 caches for matching KV caches:- Traverses the HiRadixTree from the root node
- Matches the token sequence prefix at page granularity (when
page_size > 1) - Automatically splits nodes for exact boundaries when matches terminate mid-node
- Returns a continuous prefix with L1 portion followed by L2 portion
- Extremely fast since no data copying is required
2. Prefetch from L3
For parts not found in L1 or L2, HiCache queries L3 storage and prefetches data proactively: Trigger Conditions:- L3 hit length exceeds threshold (default: 256 tokens, configurable)
best_effort: Terminates immediately when GPU can execute prefill (minimal latency)wait_complete: Waits for all prefetch operations (highest cache hit rate)timeout: Balances latency and cache hit rate with configurable timeout
timeout strategy, the timeout is computed as:
3. Write-back
After prefill computation, newly generated KV caches are written back to L2 and L3: Write-back Policies:write_through: Immediately writes to all tiers (strongest caching benefits when bandwidth is sufficient)write_through_selective: Writes only hot data exceeding access frequency threshold (reduces I/O overhead)write_back: Writes to next level only on eviction (suitable for limited storage capacity)
Performance Optimizations
Zero-Copy Data Transfers
HiCache supports passing memory addresses and sizes directly when transferring data from L2 to L3, minimizing data copies and improving performance.Optimized Memory Layouts
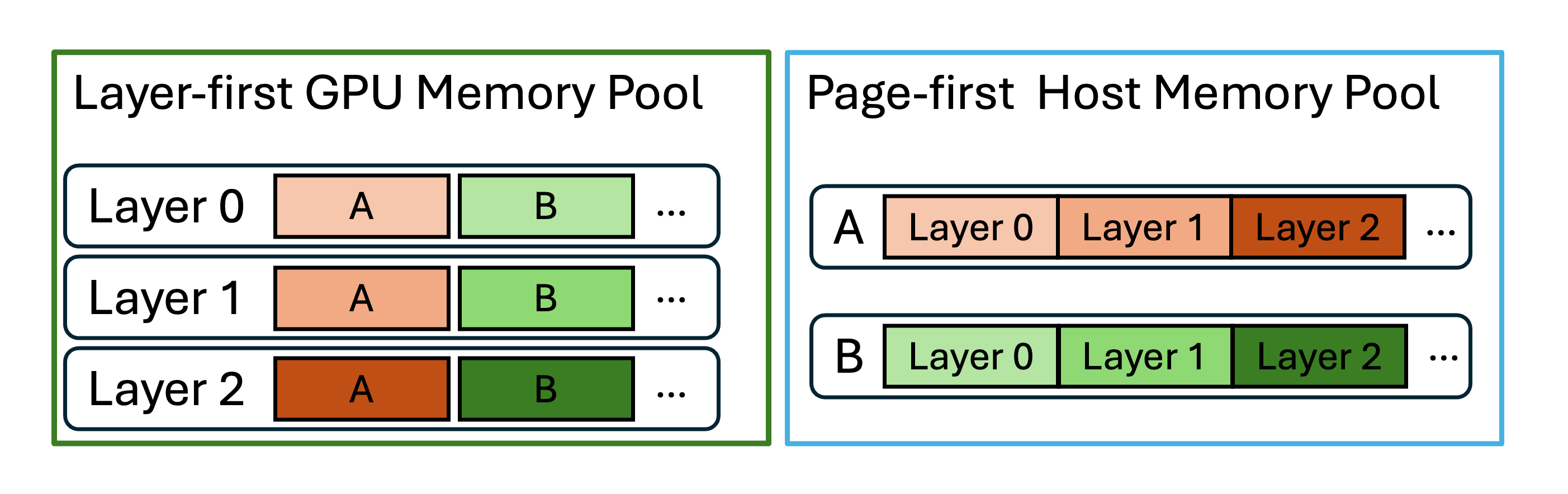
HiCache supports multiple memory layouts for L2 host memory:layer_first: Compatible with GPU computation kernels (default for GPU memory)page_first: All KV cache data for the same page in contiguous memory, enabling zero-copy transfers to L3page_first_direct: Groups all tokens of a given layer within a page, allowing aggregated page-layer transfers from L2 to GPU
CPU-to-GPU Transfer Optimizations
- Compute-Transfer Overlap: During prefill, concurrently loads layer N+1 while computing layer N
- GPU-assisted I/O Kernels: Custom kernels achieve up to 3× higher transfer speed compared to baseline
cudaMemcpyAsync
Multi-Rank Synchronization
During multi-GPU parallel computation (e.g., tensor parallelism), HiCache usesall_reduce operations to ensure consistent states across ranks:
all_reduce(op=min)ensures all ranks obtain same L3 hit count- Guarantees consensus on prefix length of successfully retrieved KV cache
MLA Optimization
For MLA (Multi-Layer Attention) models under multi-TP, all ranks hold identical KV data. HiCache optimizes write-back by having only one rank initiate the operation, preventing redundant storage.Configuration Parameters
Core Parameters
Enable hierarchical cache functionality. Required to use HiCache.
Ratio of host KV cache memory pool size to device pool size. For example, a value of 2 means the host memory pool is twice as large as the device memory pool. Must be greater than 1.
Size of host KV cache memory pool in gigabytes per rank. Overrides
--hicache-ratio if set. For example, --hicache-size 30 allocates 30GB (1GB = 1e9 bytes) per rank. With 8 ranks, total memory is 240GB.In general, a larger HiCache size leads to higher cache hit rate, which improves prefill performance. However, the relationship is not linear. Once most reusable KV data is cached, further increases yield marginal gains. Set based on workload characteristics.
Number of tokens per page. Determines granularity of KV cache storage and retrieval. Larger pages reduce metadata overhead and improve I/O efficiency but may lower cache hit rate when only part of a page matches. For long common prefixes, larger pages improve performance; for diverse prefixes, smaller pages are better.
Prefetch Configuration
Controls when prefetching from storage should stop. Options:
best_effort: Prefetch without blocking (minimal latency)wait_complete: Wait for prefetch completion (highest hit rate)timeout: Balance latency and hit rate with timeout (recommended for production)
Write Policy
Controls how data is written from faster to slower memory tiers. Options:
write_through: Immediately writes to all tiers (strongest caching benefits)write_through_selective: Uses hit-count tracking to back up only frequently accessed datawrite_back: Writes to slower tiers only on eviction (reduces I/O load)
I/O Backend
Choose I/O backend for KV cache transfer between CPU and GPU. Options:
direct: Standard CUDA memory copy operationskernel: GPU-assisted I/O kernels (recommended for better performance)
Memory Layout
Memory layout for the host memory pool. Options:
layer_first: Compatible with GPU computation kernelspage_first: Optimized for I/O efficiency with zero-copy (only compatible withkernelbackend)page_first_direct: Aggregated page-layer transfers (compatible withdirectbackend and FA3)
Storage Backend
Choose the storage backend for the L3 tier. Built-in options:
file: Simple file-based storage for demonstrationmooncake: High-performance RDMA-based caching systemhf3fs: Kubernetes-native distributed storagenixl: Unified API for various storage pluginsaibrix: Production-ready KVCache offloading frameworkdynamic: Custom backend loaded dynamically
Extra configuration for storage backend. Can be either:
- A JSON string:
'{"prefetch_threshold":512}' - A config file path (prepend with
@):"@config.toml"
Use LMCache as an alternative hierarchical cache solution.
Storage Backends
HiCache provides unified interfaces for various L3 storage backends:Mooncake
High-performance caching system leveraging RDMA and multi-NIC resources for zero-copy, ultra-fast data transfers.HF3FS
Kubernetes-native distributed storage solution with operator-based deployment.NIXL
Provides unified API for accessing various storage plugins including DeepSeek’s 3FS, GPU Direct Storage (GDS), and Amazon S3-compatible object storage.AIBrix KVCache
Production-ready KVCache offloading framework enabling efficient memory tiering and low-overhead cross-engine reuse.LMCache
An alternative efficient KV cache layer for enterprise-scale LLM inference, providing a different solution to HiCache.Runtime Attach/Detach
HiCache supports dynamically attaching/detaching the L3 storage backend at runtime without restarting the server.Query Current Backend
Attach Storage Backend
Detach Storage Backend
Detach only stops using the L3 storage backend and stops prefetch/backup threads. It does not automatically delete data stored in remote backends.
Integration with PD Disaggregation
HiCache works seamlessly with PD (Prefill-Decode) Disaggregation deployment mode:- Prefill-only HiCache: Enable HiCache only on Prefill nodes for KV cache sharing among Prefill instances
- Full HiCache with async offloading: Enable HiCache on Prefill nodes and async offloading on Decode nodes for multi-turn dialogue scenarios
Heterogeneous TP Support
HiCache storage supports cross-cluster KV reuse when different deployments use different TP sizes (e.g.,tp=4 and tp=8) sharing the same storage backend namespace.
Custom Storage Backend Integration
To integrate a custom storage backend:-
Implement three core methods:
get(key): Retrieve value by keyexists(key): Check key existenceset(key, value): Store key-value pair
- Use dynamic loading:
Best Practices
Memory Configuration
Set
--hicache-ratio or --hicache-size based on workload. Larger values improve hit rate but with diminishing returns after hot data is cached.Layout Selection
Use
page_first_direct with direct backend for best compatibility. Use page_first with kernel backend for maximum I/O efficiency.Prefetch Policy
Use
timeout policy in production with tuned timeout parameters to meet SLOs while maximizing cache hits.Write Policy
Use
write_through when bandwidth is sufficient. Use write_through_selective to reduce I/O overhead for mixed workloads.