System architecture
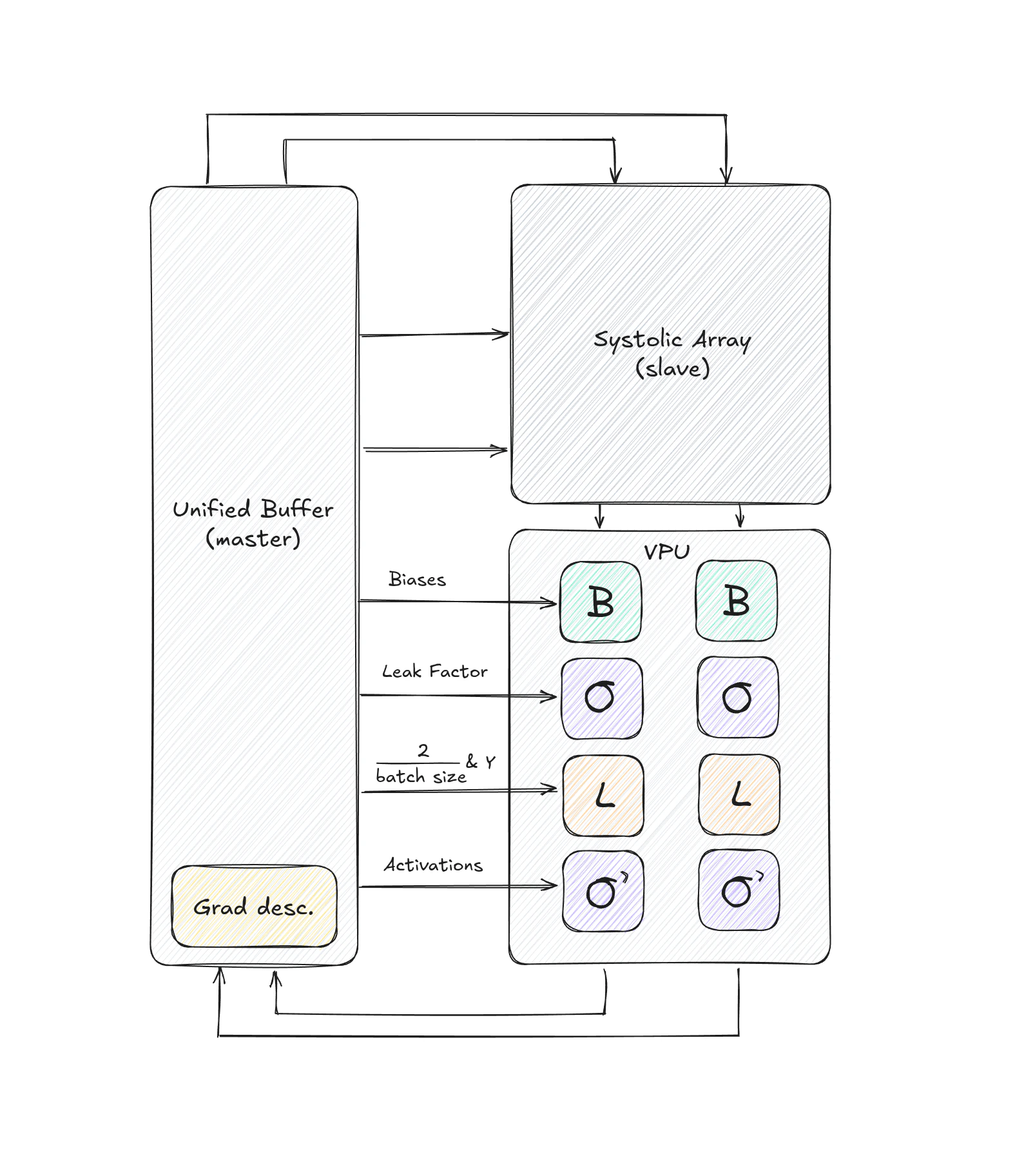
- Processing element (PE) - The fundamental computational unit
- Systolic array - A 2D grid of processing elements
- Vector processing unit (VPU) - Element-wise operations pipeline
- Unified buffer (UB) - Dual-port memory for intermediate values
- Control unit - Instruction decoder and system controller
Top-level module
The top-level TPU module connects all major components:Data flow
The TPU follows a specific data flow pattern:Forward pass
- Input loading: Matrices are loaded from the host into the unified buffer
- Systolic computation: Input and weight matrices flow through the systolic array
- Inputs flow horizontally (left to right)
- Weights flow vertically (top to bottom)
- Partial sums accumulate vertically
- VPU processing: Results pass through the VPU pipeline:
- Bias addition
- Leaky ReLU activation
- Result storage: Outputs are written back to the unified buffer
Backward pass
- Loss computation: VPU computes loss derivatives
- Gradient computation: Systolic array computes weight and activation gradients
- Activation derivative: VPU applies activation function derivatives
- Parameter update: Gradient descent modules update weights and biases
Key features
Fixed-point arithmetic
All computations use 16-bit fixed-point representation (Q8.8 format):- 8 bits for integer part
- 8 bits for fractional part
- Signed values using two’s complement
The fixed-point library in
fixedpoint.sv provides modules for multiplication (fxp_mul), addition (fxp_add), and other arithmetic operations with overflow detection.Pipelined architecture
The VPU implements a pipelined architecture where multiple modules can process different data simultaneously:Configurable dimensions
The systolic array width is configurable via theSYSTOLIC_ARRAY_WIDTH parameter:
- Default: 2×2 array
- Scalable to larger dimensions (e.g., 256×256, 512×512)
Performance characteristics
Throughput
Each processing element performs one multiply-accumulate (MAC) operation per clock cycle:- 2×2 array: 4 MACs per cycle
- Single-cycle operation for activated PEs
Memory bandwidth
The unified buffer provides:- Dual-port read/write capability
- Staggered data delivery for systolic flow
- Transpose support for efficient matrix operations
Implementation details
Clock and reset
All modules use synchronous design:- Positive edge-triggered flip-flops
- Asynchronous active-high reset
Data widths
Standardized 16-bit data paths throughout:- Input activations: 16 bits signed
- Weights: 16 bits signed
- Partial sums: 16 bits signed
- Bias values: 16 bits signed
Next steps
Explore each component in detail:Processing element
Learn about the PE multiply-accumulate unit
Systolic array
Understand the 2D PE grid architecture
Vector processing unit
Explore the VPU pipeline stages
Unified buffer
Discover the memory architecture