
Benchmark Results
We evaluate all OpenCLIP models on a comprehensive suite of 38 datasets in zero-shot settings, following the methodology from Gadre et al., 2023 (DataComp).Evaluation Suite Overview
The 38-dataset evaluation suite includes:Classification Datasets (35)
- ImageNet variants: ImageNet-1k, ImageNet-V2, ImageNet-Sketch, ImageNet-A, ImageNet-O, ImageNet-R
- Fine-grained: FGVC Aircraft, Stanford Cars, Oxford Flowers-102, Oxford-IIIT Pet, Food-101
- General: CIFAR-10, CIFAR-100, Caltech-101, STL-10, MNIST, SVHN
- Specialized: EuroSAT, RESISC45, PatchCamelyon, Describable Textures, Country211
- Distribution shift: ObjectNet, GTSRB, KITTI Vehicle Distance
- Scene understanding: SUN397, Pascal VOC 2007
- Reasoning: CLEVR Counts, CLEVR Distance, Rendered SST2
- Domain-specific: iWildCam, Camelyon17, FMoW, Dollar Street, GeoDE
Retrieval Datasets (3)
- Flickr30k: Image-to-text and text-to-image retrieval
- MSCOCO: Caption retrieval tasks
- WinoGAViL: Visual reasoning retrieval
Full Results
Download complete results for all models:- Full results (all 38 datasets)
- Classification results (35 datasets)
- Retrieval results
- Multilingual retrieval results
Top Performing Models
ImageNet Zero-Shot Top-1 Accuracy
Here are the best performing models on ImageNet-1k zero-shot classification:| Model | Training Data | Resolution | ImageNet Acc. | Avg (38 datasets) |
|---|---|---|---|---|
| ViT-H-14-378-quickgelu | DFN-5B | 378px | 84.4% | 70.8% |
| ViT-H-14-quickgelu | DFN-5B | 224px | 83.4% | 69.6% |
| ViT-SO400M-14-SigLIP-384 | WebLI | 384px | 83.1% | 69.2% |
| EVA02-E-14-plus | LAION-2B | 224px | 82.0% | 69.3% |
| ViT-bigG-14-CLIPA-336 | DataComp-1B | 336px | 83.1% | 68.4% |
| ViT-SO400M-14-SigLIP | WebLI | 224px | 82.0% | 68.1% |
| ViT-H-14-CLIPA-336 | DataComp-1B | 336px | 81.8% | 66.8% |
| ViT-L-14-quickgelu | DFN-2B | 224px | 81.4% | 66.9% |
| ViT-L-16-SigLIP-384 | WebLI | 384px | 82.1% | 66.8% |
| ViT-L-14 | DataComp-1B | 224px | 79.2% | 66.3% |
OpenCLIP vs. State-of-the-Art
Comparison with other leading CLIP implementations:| Model | Source | ImageNet Acc. | Training Data |
|---|---|---|---|
| ViT-H-14-378 | OpenCLIP (DFN) | 84.4% | DFN-5B |
| ViT-gopt-16-SigLIP2-384 | SigLIP2 | 85.0% | WebLI (multi-lang) |
| PE-Core-bigG-14-448 | PE | 85.4% | MetaCLIP-5.4B |
| ViT-SO400M-14-SigLIP-384 | SigLIP | 83.1% | WebLI |
| ViT-H-14 | OpenCLIP (DFN) | 83.4% | DFN-5B |
| ViT-L-14 | OpenCLIP (DataComp) | 79.2% | DataComp-1B |
| ViT-bigG-14 | OpenCLIP (LAION) | 80.1% | LAION-2B |
| ViT-L-14 | OpenAI | 75.5% | WIT |
| ViT-L-14 | OpenCLIP (LAION) | 75.3% | LAION-2B |
Detailed Model Performance
ViT Models on LAION-2B
ViT-B/32 (224px)
- ImageNet Zero-Shot: 65.6%
- Training: 112 A100 GPUs, batch size 46,592
- Dataset: LAION-2B English subset
ViT-L/14 (224px)
- ImageNet Zero-Shot: 75.3%
- Training: JUWELS Booster supercomputer
- Samples Seen: 32B
- Special Note: Uses inception-style normalization (mean/std of 0.5) instead of OpenAI’s normalization
ViT-H/14 (224px)
- ImageNet Zero-Shot: 78.0%
- Training: JUWELS Booster
- Samples Seen: 32B
- Parameters: 986M
ViT-g/14 (224px)
- ImageNet Zero-Shot: 76.6%
- Training: JUWELS Booster
- Samples Seen: 12B (shorter schedule)
- Note: Despite lower ImageNet score, excels at some OOD and retrieval tasks
ConvNext Models
| Model | Dataset | Resolution | ImageNet Acc. |
|---|---|---|---|
| ConvNext-Base | LAION-2B | 256px | 71.5% |
| ConvNext-Large | LAION-2B | 320px | 76.9% |
| ConvNext-XXLarge | LAION-2B | 256px | 79.5% |
DataComp Models
Trained on DataComp-1B, following the DataComp paper:| Model | Pretrained Tag | ImageNet Acc. | Avg (38 datasets) |
|---|---|---|---|
| ViT-L/14 | datacomp_xl_s13b_b90k | 79.2% | 66.3% |
| ViT-B/16 | datacomp_xl_s13b_b90k | 73.5% | 61.5% |
| ViT-B/32 | datacomp_xl_s13b_b90k | 69.2% | 58.0% |
Multilingual Models
xlm-roberta-base + ViT-B/32
- Dataset: LAION-5B
- ImageNet (English): 62.3%
- ImageNet (Italian): 43%
- ImageNet (Japanese): 37%
- First multilingual OpenCLIP model
xlm-roberta-large + ViT-H/14
- Training: LiT methodology (frozen image tower)
- ImageNet (English): 77.0%
- ImageNet (Italian): 56%
- ImageNet (Japanese): 53%
- ImageNet (Chinese): 55.7%
LAION-400M Results
ViT-B/32 (224px)
- ImageNet Zero-Shot: 63.0%
- Training: 128 A100 GPUs, ~36 hours (4,600 GPU-hours)
- Batch Size: 32,768 (256 per GPU)
- Result: Matches OpenAI’s ViT-B/32 performance
ViT-B/16 (224px)
- ImageNet Zero-Shot: 67.1%
- Training: 176 A100 GPUs, ~61 hours (10,700 GPU-hours)
- Batch Size: 33,792 (192 per GPU)
ViT-B/16+ (240px)
- ImageNet Zero-Shot: 69.2%
- Architecture: Wider than B/16 (vision: 768→896, text: 512→640)
- Training: 224 A100 GPUs, ~61 hours (13,620 GPU-hours)
- Batch Size: 35,840 (160 per GPU)
ViT-L/14 (224px)
- ImageNet Zero-Shot: 72.8%
- Training: 400 A100 GPUs, ~127 hours (50,800 GPU-hours)
- Batch Size: 38,400 (96 per GPU)
- Features: Gradient checkpointing enabled
Per-Dataset Performance
Top Model Performance by Dataset Type
Fine-Grained Classification:- FGVC Aircraft: 72.2% (ViT-H-14-378)
- Stanford Cars: 96.0% (ViT-H-14-378)
- Oxford Flowers: 89.4% (ViT-H-14-378)
- Oxford Pets: 97.0% (ViT-H-14-378)
- EuroSAT: 75.7% (EVA02-E-14-plus)
- RESISC45: 75.9% (ViT-H-14-378)
- PatchCamelyon: 82.4% (ViT-H-14-378)
- Camelyon17: 72.1% (ViT-H-14-378)
- ImageNet-A: 82.3% (EVA02-E-14-plus)
- ImageNet-R: 94.6% (EVA02-E-14-plus)
- ObjectNet: 83.6% (ViT-H-14-378)
Training Curves
ViT-B/32 on LAION-400M
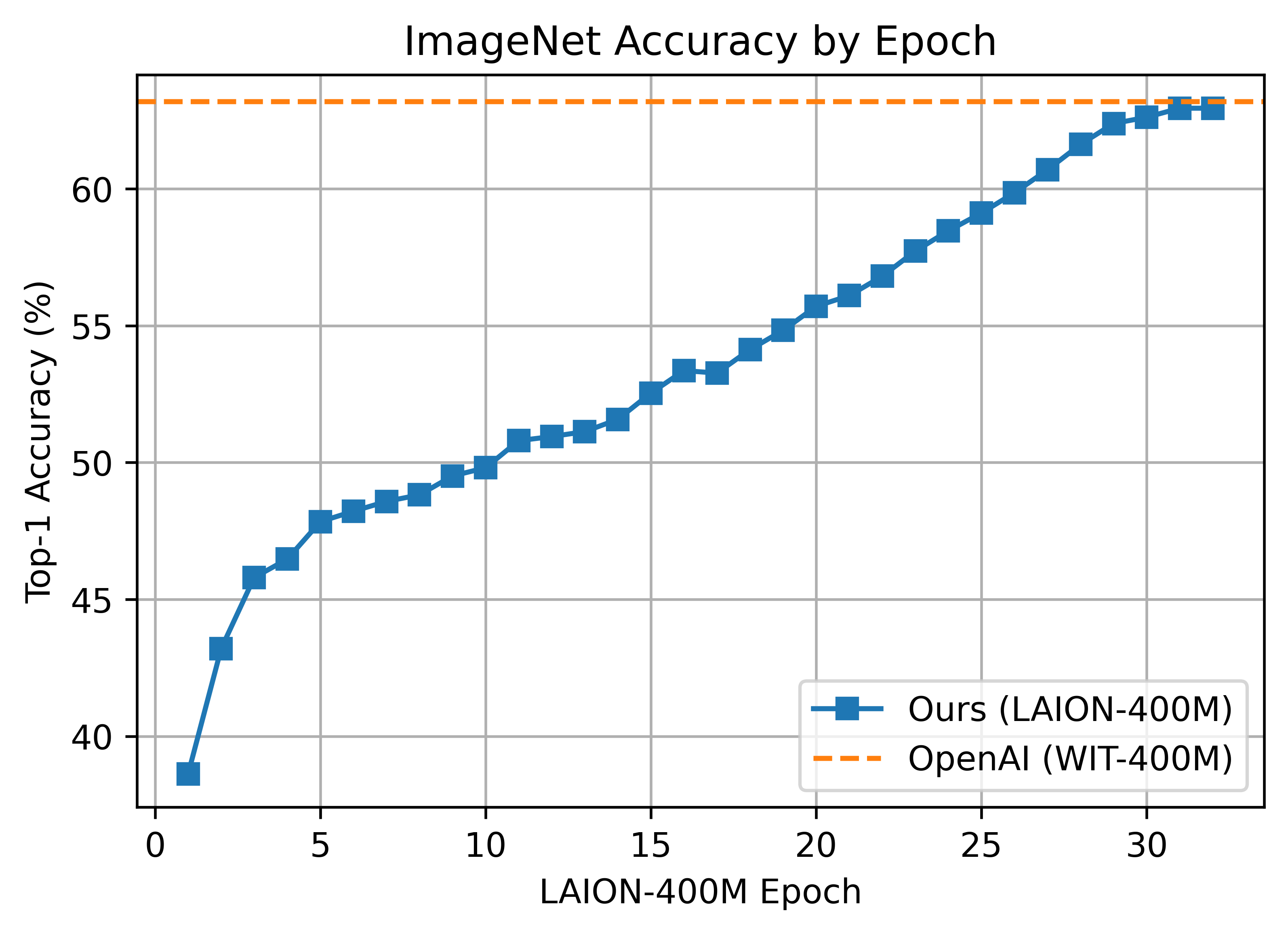
Comparison with OpenAI
How to Use These Results
Loading Top Models
Running Your Own Evaluation
Use CLIP_benchmark for systematic evaluation:Key Findings
Scale Matters: Larger models (ViT-H, ViT-g) consistently outperform smaller ones, especially on challenging datasets.
Data Quality: DataComp and DFN models show that curated datasets can outperform raw web data.
Resolution: Higher resolution inputs (336px, 378px) provide significant gains over 224px.
Multilingual: XLM-RoBERTa text encoders enable strong multilingual performance without sacrificing English accuracy.
Citation
If you use these benchmarks, please cite:Next Steps
- Explore zero-shot evaluation during training
- Understand evaluation metrics in detail
- Browse all pre-trained models