Overview
Adopting the original design from SGLang, Mini-SGLang implements a Radix Cache to manage the KV cache intelligently. Instead of recomputing the KV cache for every request, the system identifies and reuses cached computations from previous requests with matching prefixes.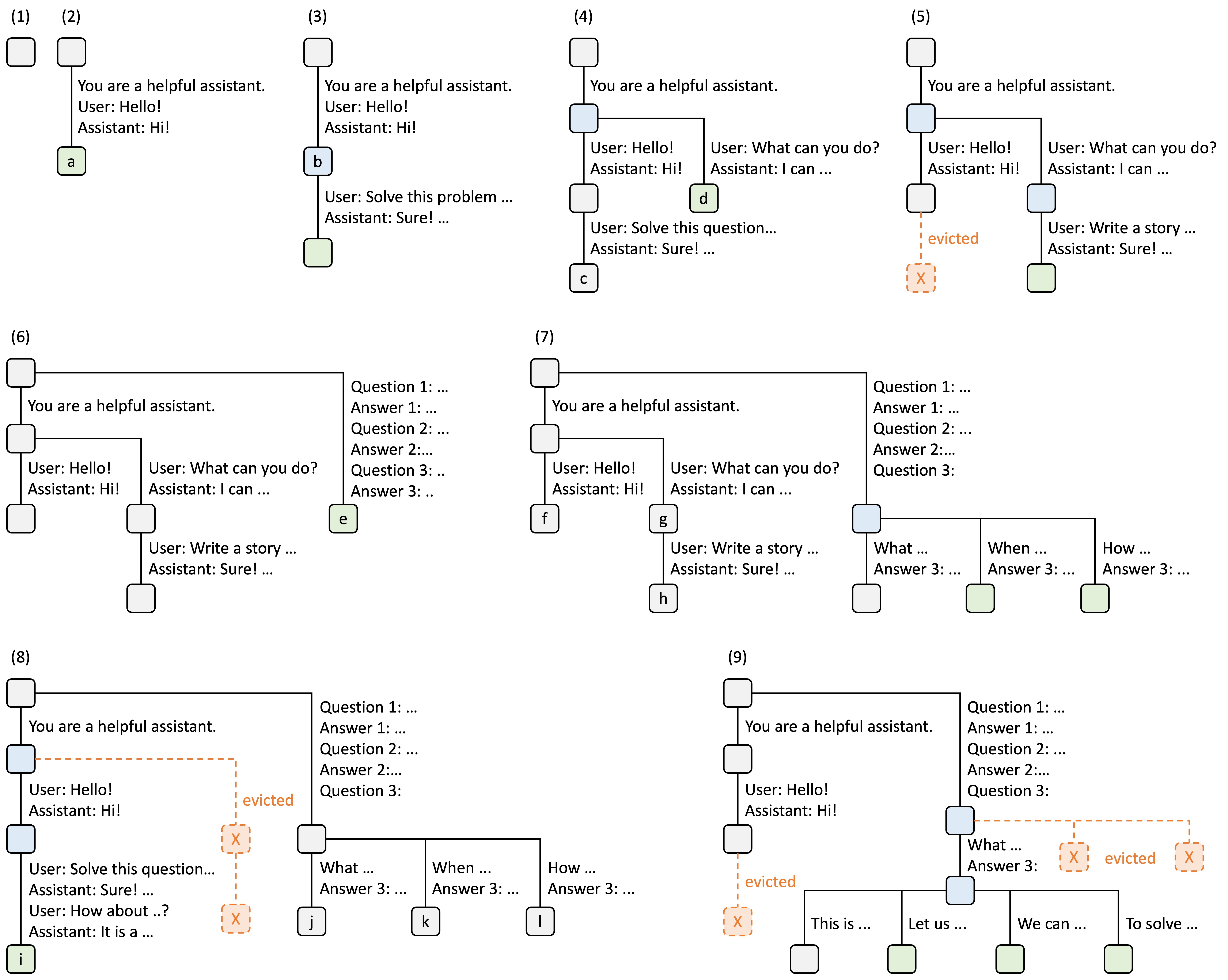 Illustration of Radix Attention from LMSYS Blog
Illustration of Radix Attention from LMSYS Blog
How It Works
Radix Tree Structure
The Radix Cache is built on a radix tree data structure where:- Nodes represent token sequences and their corresponding KV cache indices
- Edges connect sequences that share common prefixes
- Root is always protected and represents the empty sequence
- Key: The token sequence (input_ids)
- Value: The physical page indices in the KV cache
- Reference count: Number of active requests using this prefix
- Timestamp: Last access time for eviction decisions
Prefix Matching
When a new request arrives, the system walks the radix tree to find the longest matching prefix:- Starts at the root node
- Checks children for matching prefixes (using page-aligned keys)
- Walks down the tree while matches are found
- Splits nodes if partial matches occur
- Returns the matched node and prefix length
Prefix matching is page-aligned based on the system’s page size. This means only complete pages are matched and reused, ensuring efficient memory management.
Cache Insertion
After processing a request, the system inserts the new sequence into the cache:Reference Counting
The system uses reference counting to protect active cache entries from eviction:- Locked (ref_count > 0): The prefix is actively used by one or more requests and cannot be evicted
- Unlocked (ref_count = 0): The prefix is cached but not in use, available for eviction if memory is needed
Cache Eviction
When memory is needed, the system evicts the least recently used (LRU) leaf nodes:- Collect evictable leaves: Find all leaf nodes with
ref_count == 0 - Heapify by timestamp: Sort by least recently accessed
- Evict until target met: Remove nodes and update parent leaf status
- Cascade eviction: If parent becomes a leaf with
ref_count == 0, it becomes evictable too
The eviction strategy is LRU (Least Recently Used) based on the timestamp of last access. Nodes are only evicted when they have no active references and are leaf nodes in the tree.
Benefits
Reduced Redundant Computation
Consider a chatbot scenario where multiple users ask similar questions:- First request: Computes KV cache for entire sequence
- Second request: Reuses KV cache for “What is the capital of”, only computes “Germany?”
- Third request: Reuses KV cache for “What is the capital of”, only computes “Italy?”
Memory Efficiency
Shared prefixes are stored only once in the cache, reducing memory footprint compared to per-request caching.Lower Latency
Reusing cached KV values eliminates redundant forward passes through transformer layers for matching prefixes, reducing time-to-first-token (TTFT).Configuration
Radix Cache is enabled by default in Mini-SGLang. To switch to a naive cache management strategy:Page Size
The page size affects cache granularity. Larger pages reduce metadata overhead but may waste memory on partial matches:Implementation Details
Key Function
The key function determines how sequences are indexed in the tree:page_size=1, the key is a single token. For larger page sizes, the key is a tuple of the first page_size tokens.
Node Splitting
When a partial match occurs, the existing node is split to create a new branch:Fast Key Comparison
Mini-SGLang uses a custom CUDA kernel for fast token sequence comparison:Related Concepts
Architecture
Understand how cache management fits into the system
Chunked Prefill
Learn about memory-efficient prefill strategies