--cache-type flag.
Overview
KV (Key-Value) cache stores intermediate attention states during LLM inference. Effective cache management can dramatically reduce computation by reusing cached states for shared prompt prefixes.Cache Strategies
Radix Cache (Default)
Radix cache implements a radix tree data structure to automatically detect and reuse shared prefixes across requests. This is the default cache management strategy. Key Features:- Automatic prefix matching and reuse
- LRU-based eviction for cache management
- Supports dynamic node splitting and merging
- Reduces redundant computation for common prefixes
minisgl.kvcache.radix_cache.RadixPrefixCache (source:~/workspace/source/python/minisgl/kvcache/radix_cache.py:101)
When to Use:
- Multi-turn conversations with shared history
- Batch processing with common system prompts
- Few-shot prompting with repeated examples
- RAG (Retrieval-Augmented Generation) with shared context
Naive Cache
Naive cache provides simple per-request cache isolation without any prefix sharing. Key Features:- No prefix matching or sharing
- Minimal memory overhead
- Simpler implementation for debugging
- Each request maintains independent cache
minisgl.kvcache.naive_cache.NaivePrefixCache (source:~/workspace/source/python/minisgl/kvcache/naive_cache.py:16)
When to Use:
- Unique requests with no shared prefixes
- Testing and debugging
- Benchmarking without cache effects
- Simple single-request scenarios
Configuration
Use the--cache-type flag to select the cache strategy:
KV cache management strategy.Choices:
radix, naiveradix: Enables automatic prefix sharing across requestsnaive: Disables prefix sharing, each request has independent cache
minisgl.server.args.py:206Radix Cache Details
How It Works
Radix cache organizes KV cache entries in a radix tree structure:- Tree Structure: Each node represents a prefix of token IDs
- Prefix Matching: Incoming requests traverse the tree to find matching prefixes
- Cache Reuse: Matched nodes provide cached KV states
- Dynamic Splitting: Nodes split when partial matches occur
- LRU Eviction: Least recently used nodes are evicted when memory is needed
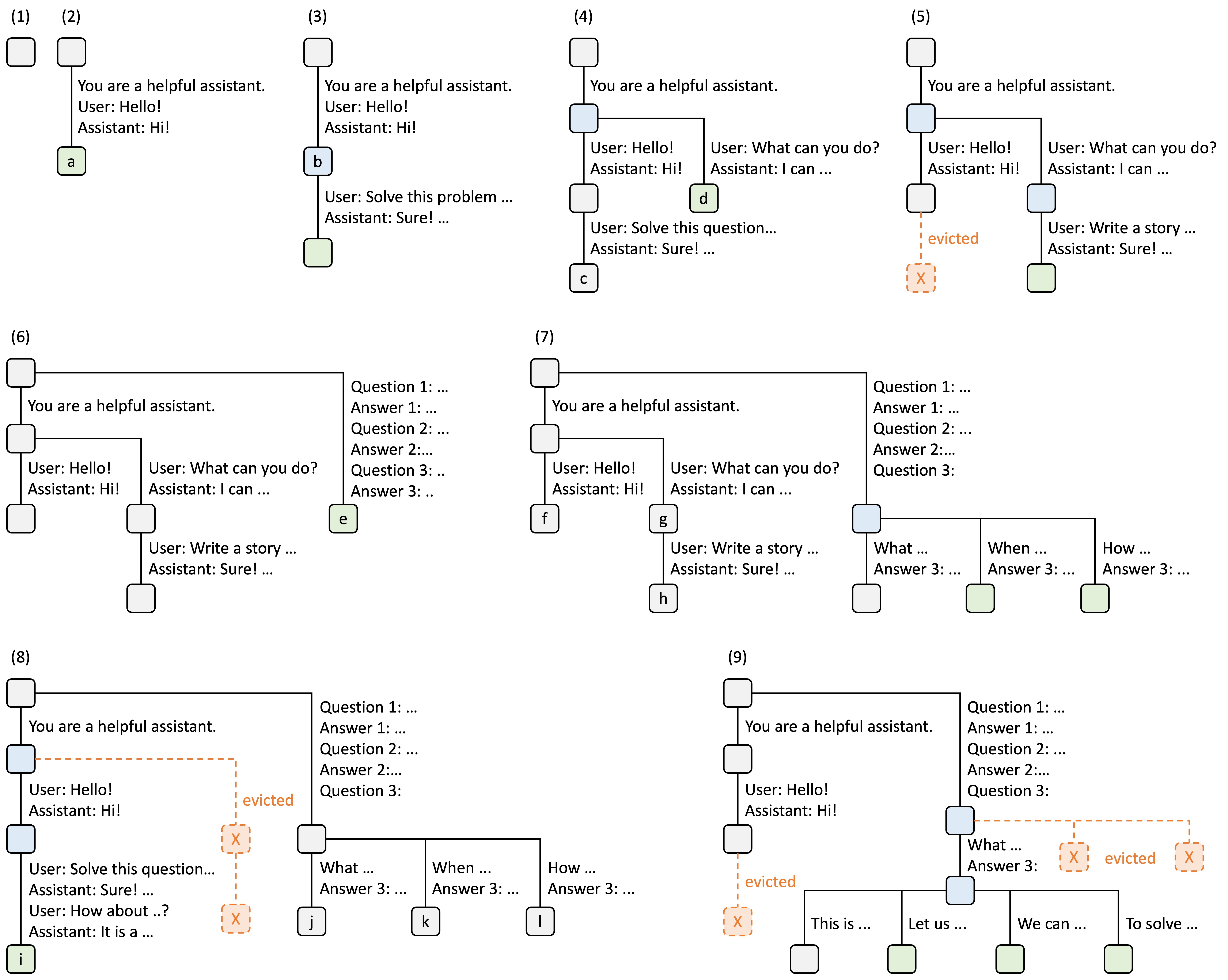 Illustration from LMSYS Blog
Illustration from LMSYS Blog
Tree Operations
Prefix Matching
Source:radix_cache.py:132
Insertion
Source:radix_cache.py:136
Eviction
Source:radix_cache.py:148
Node Structure
Source:radix_cache.py:17
Each RadixTreeNode contains:
_key: Token IDs for this node_value: Physical page indices in KV cache_length: Number of tokenschildren: Dictionary of child nodesref_count: Reference count for protection from evictiontimestamp: LRU timestamp
Memory Management
Radix cache tracks two types of memory:- Protected Size: Nodes currently in use (ref_count > 0)
- Evictable Size: Unused nodes available for eviction (ref_count == 0)
radix_cache.py:181
Page Alignment
Radix cache aligns all operations to page boundaries: Source:radix_cache.py:137
Naive Cache Details
Implementation
Naive cache provides minimal implementation: Source:naive_cache.py:16
Memory Overhead
Naive cache has minimal memory overhead:- No tree structure
- No metadata tracking
- Simple cache handle objects
Performance Comparison
Radix Cache Benefits
Scenario: 100 requests with shared 500-token system prompt- Without radix cache: 100 × 500 = 50,000 tokens computed
- With radix cache: 500 (first request) + 100 × unique tokens
- Speedup: Up to 50× for prompt processing
When Naive Outperforms Radix
- No shared prefixes: Radix overhead without benefits
- Highly variable requests: Rare cache hits
- Small batch sizes: Overhead dominates
Usage Examples
Multi-Turn Chat with Radix Cache
- Reuses chat history across turns
- Reduces latency for follow-up questions
- Improves throughput for concurrent conversations
Batch Processing with Shared Prompts
- Shares system prompt across all requests
- Reuses few-shot examples
- Dramatically reduces prefill time
Simple Testing with Naive Cache
- Simpler debugging
- Predictable memory usage
- No cache-related side effects
Shell Mode (Auto Radix Cache)
/reset to clear cache and start a new session.
Page Size Interaction
Cache management interacts with page size (--page-size):
- Radix cache: Aligns all cache entries to page boundaries
- Smaller page size: More granular cache reuse, higher overhead
- Larger page size: Less granular reuse, lower overhead
--page-size 1 with radix cache for maximum reuse granularity.
Memory Ratio Tuning
The--memory-ratio flag controls how much GPU memory is allocated for KV cache:
- Higher memory ratio → More cache reuse opportunities
- Lower memory ratio → More frequent evictions
Design Origin
Radix cache is adopted from the original SGLang design, which introduced this optimization for efficient KV cache management in LLM serving. Reference: SGLang Blog Post on Radix AttentionSource Code Reference
Cache management implementations:- Registry:
kvcache/__init__.py:24(SUPPORTED_CACHE_MANAGER) - Radix Cache:
kvcache/radix_cache.py:101(RadixPrefixCache) - Naive Cache:
kvcache/naive_cache.py:16(NaivePrefixCache) - Base Interface:
kvcache/base.py(BasePrefixCache)
- CLI Flag:
server/args.py:206(--cache-type)