

BASE Properties
BASE is often used to describe the properties of NoSQL databases. In comparison with the CAP Theorem, BASE chooses availability over consistency.- Basically available - the system guarantees availability
- Soft state - the state of the system may change over time, even without input
- Eventual consistency - the system will become consistent over a period of time, given that the system doesn’t receive input during that period
NoSQL Database Types
Key-value store
Abstraction: hash tableA key-value store generally allows for O(1) reads and writes and is often backed by memory or SSD. Data stores can maintain keys in lexicographic order, allowing efficient retrieval of key ranges. Key-value stores can allow for storing of metadata with a value. Key-value stores provide high performance and are often used for simple data models or for rapidly-changing data, such as an in-memory cache layer. Since they offer only a limited set of operations, complexity is shifted to the application layer if additional operations are needed. A key-value store is the basis for more complex systems such as a document store, and in some cases, a graph database.
Use cases and examples
Use cases and examples
Common use cases:
- In-memory cache layer
- Session storage
- User preferences and settings
- Shopping cart data
- Rapidly-changing data
- Redis
- Memcached
- Amazon DynamoDB (also supports documents)
- Riak
Document store
Abstraction: key-value store with documents stored as valuesA document store is centered around documents (XML, JSON, binary, etc), where a document stores all information for a given object. Document stores provide APIs or a query language to query based on the internal structure of the document itself. Note, many key-value stores include features for working with a value’s metadata, blurring the lines between these two storage types. Based on the underlying implementation, documents are organized by collections, tags, metadata, or directories. Although documents can be organized or grouped together, documents may have fields that are completely different from each other. Some document stores like MongoDB and CouchDB also provide a SQL-like language to perform complex queries. DynamoDB supports both key-values and documents. Document stores provide high flexibility and are often used for working with occasionally changing data.
Use cases and examples
Use cases and examples
Common use cases:
- Content management systems
- User profiles and preferences
- E-commerce product catalogs
- Event logging
- Mobile application data
- Real-time analytics
- MongoDB
- CouchDB
- Amazon DynamoDB
- Elasticsearch
- RavenDB
Wide column store
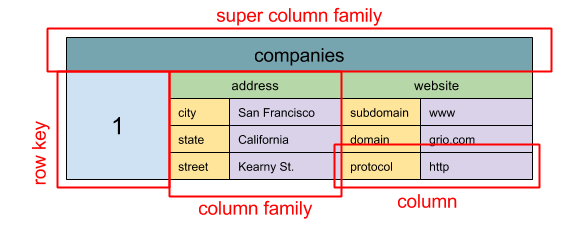
Abstraction: nested map ColumnFamily<RowKey, Columns<ColKey, Value, Timestamp>>
A wide column store’s basic unit of data is a column (name/value pair). A column can be grouped in column families (analogous to a SQL table). Super column families further group column families. You can access each column independently with a row key, and columns with the same row key form a row. Each value contains a timestamp for versioning and for conflict resolution.
Google introduced Bigtable as the first wide column store, which influenced the open-source HBase often-used in the Hadoop ecosystem, and Cassandra from Facebook. Stores such as BigTable, HBase, and Cassandra maintain keys in lexicographic order, allowing efficient retrieval of selective key ranges.
Wide column stores offer high availability and high scalability. They are often used for very large data sets.
Use cases and examples
Use cases and examples
Common use cases:
- Time series data
- Historical records
- High-write, low-read workloads
- IoT sensor data
- Analytics and big data
- Recommendation engines
- Apache Cassandra
- Apache HBase
- Google Bigtable
- ScyllaDB
Graph database
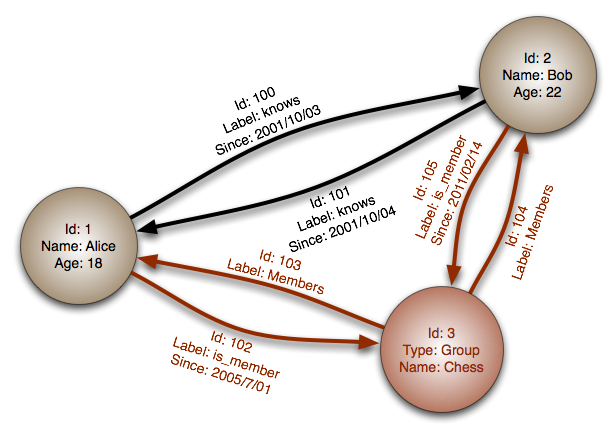
Abstraction: graphIn a graph database, each node is a record and each arc is a relationship between two nodes. Graph databases are optimized to represent complex relationships with many foreign keys or many-to-many relationships. Graphs databases offer high performance for data models with complex relationships, such as a social network. They are relatively new and are not yet widely-used; it might be more difficult to find development tools and resources. Many graphs can only be accessed with REST APIs.
Use cases and examples
Use cases and examples
Common use cases:
- Social networks (friends, followers, connections)
- Recommendation engines
- Fraud detection
- Knowledge graphs
- Network and IT operations
- Access control and permissions
- Neo4j
- Amazon Neptune
- ArangoDB
- OrientDB
- Twitter FlockDB