Common Data Structures in Daily Use
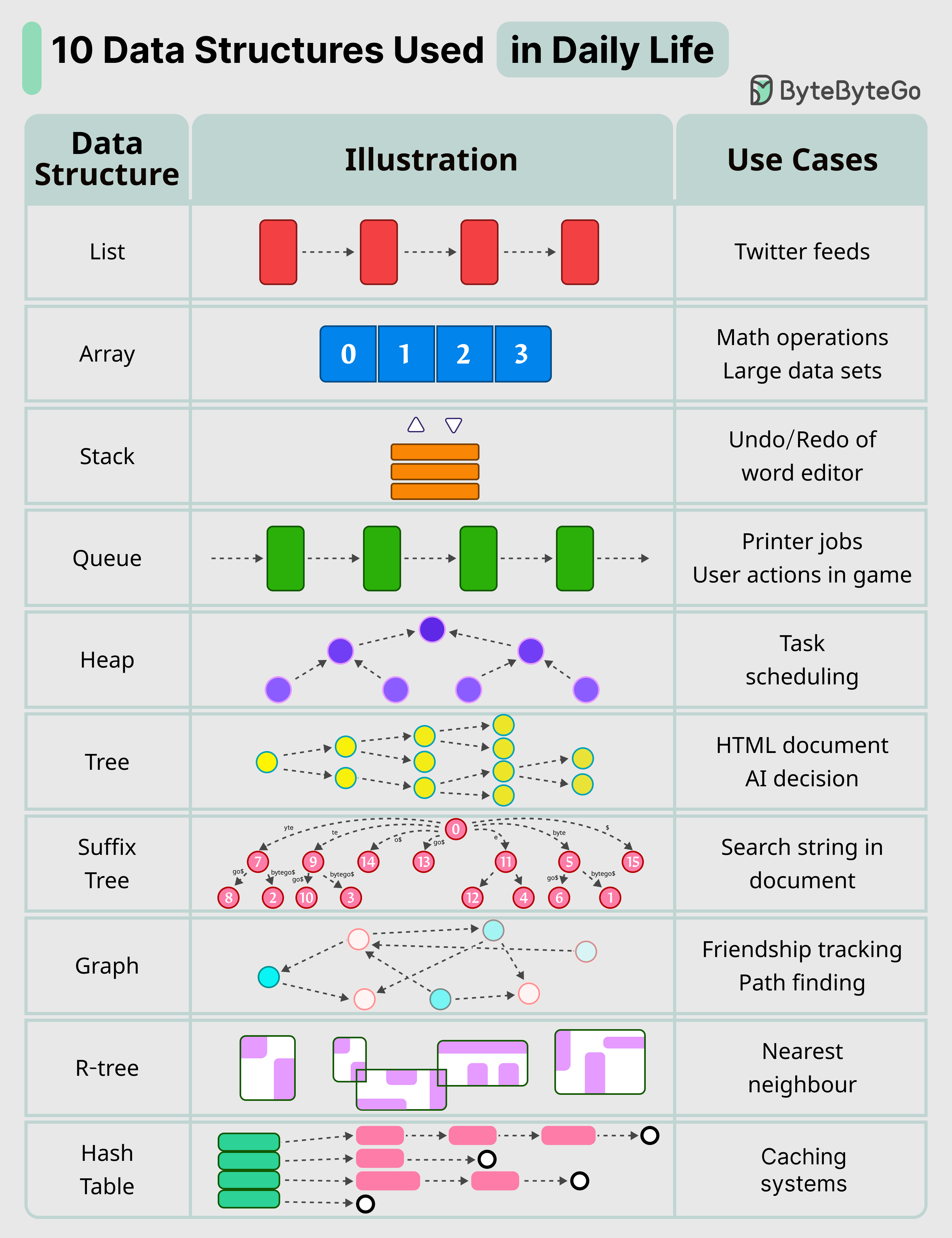 Here are 10 key data structures we use every day:
Here are 10 key data structures we use every day:
List
Real-World Use: Keep your Twitter feeds
- Sequential access
- Dynamic sizing
- Insertion/deletion at ends
- Used in social media feeds, playlists
Stack
Real-World Use: Support undo/redo of the word editor
- LIFO (Last In, First Out)
- Push and pop operations
- Function call stack
- Browser history, text editors
Queue
Real-World Use: Keep printer jobs, or send user actions in-game
- FIFO (First In, First Out)
- Enqueue and dequeue
- Task scheduling
- Message queues, BFS algorithms
Hash Table
Real-World Use: Caching systems
- Key-value pairs
- O(1) average lookup
- Hash function
- Databases, caches, dictionaries
Array
Real-World Use: Math operations
- Fixed size (in most languages)
- Contiguous memory
- Random access O(1)
- Matrix operations, images
Heap
Real-World Use: Task scheduling
- Priority queue implementation
- Min-heap or max-heap
- O(log n) insertion/deletion
- Priority scheduling, top K problems
Tree
Real-World Use: Keep the HTML document, or for AI decision
- Hierarchical structure
- Parent-child relationships
- Various traversals
- DOM, file systems, decision trees
Suffix Tree
Real-World Use: For searching string in a document
- String matching
- Pattern search O(m)
- Space-intensive
- Full-text search, DNA sequencing
Graph
Real-World Use: For tracking friendship, or path finding
- Vertices and edges
- Directed or undirected
- Weighted or unweighted
- Social networks, maps, dependencies
R-Tree
Real-World Use: For finding the nearest neighbor
- Spatial indexing
- Multi-dimensional data
- Bounding boxes
- Geospatial queries, mapping
Each data structure is optimized for specific operations. Understanding their trade-offs is crucial for system design.
Database Data Structures
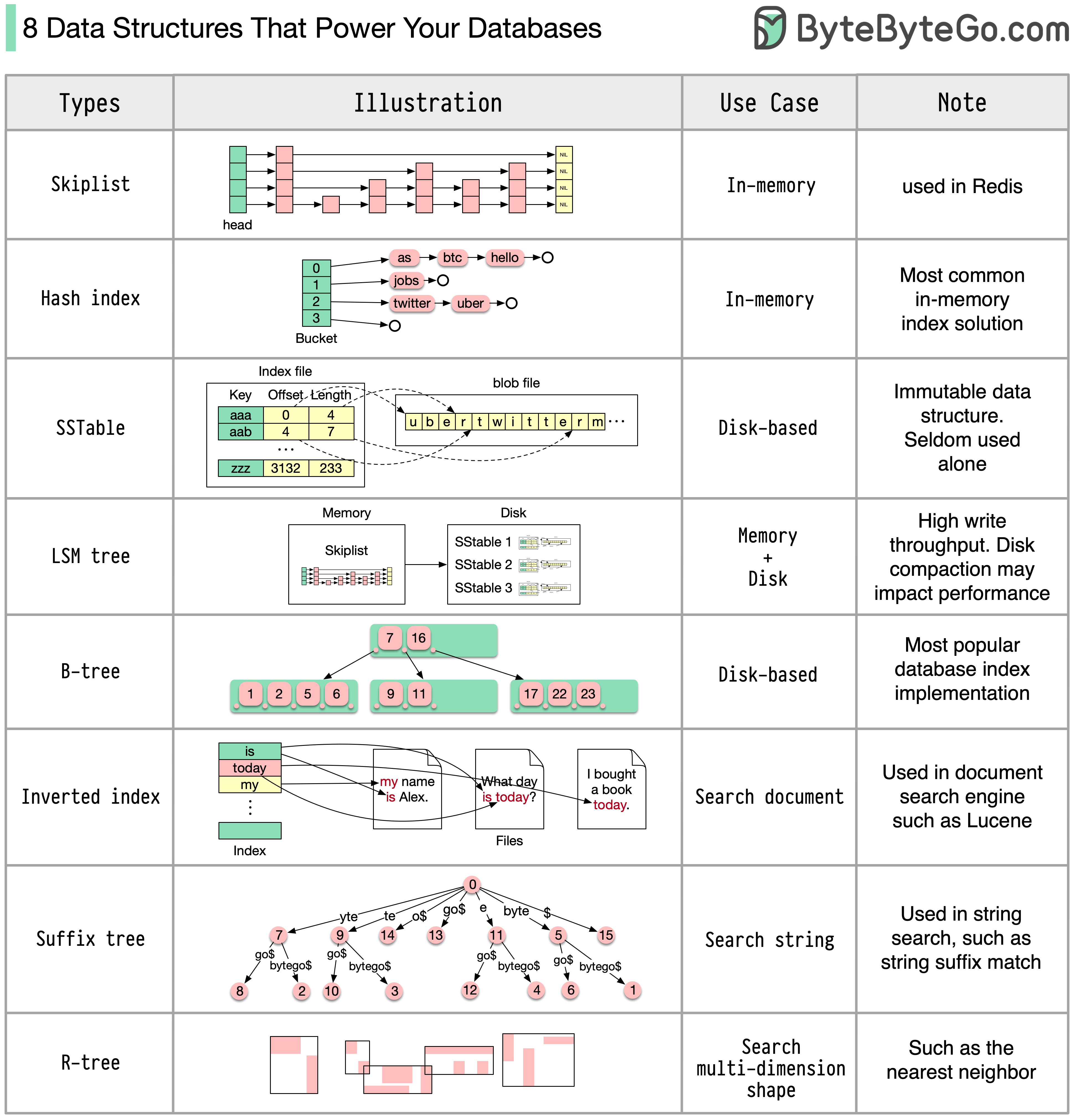 The choice of data structure will vary depending on your use case. Data can be indexed in memory or on disk. Data formats vary, such as numbers, strings, geographic coordinates, etc. The system might be write-heavy or read-heavy. All of these factors affect your choice of database index format.
The choice of data structure will vary depending on your use case. Data can be indexed in memory or on disk. Data formats vary, such as numbers, strings, geographic coordinates, etc. The system might be write-heavy or read-heavy. All of these factors affect your choice of database index format.
Popular Database Index Structures
Skiplist
Skiplist
A common in-memory index type.Characteristics:
- Probabilistic data structure
- Multiple levels of linked lists
- O(log n) search, insert, delete
- Simpler than balanced trees
- Redis (sorted sets)
- In-memory databases
- Concurrent data structures
- ✅ Simple implementation
- ✅ Good concurrency
- ❌ Extra memory for pointers
- ❌ Probabilistic guarantees
Hash Index
Hash Index
A very common implementation of the “Map” data structure (or “Collection”).Characteristics:
- Direct addressing
- O(1) average lookup
- Hash function + buckets
- Collision handling
- Key-value stores
- Database hash indexes
- Cache implementations
- ✅ Fast lookups
- ✅ Fast inserts
- ❌ No range queries
- ❌ No ordered traversal
SSTable
SSTable
Immutable on-disk “Map” implementation.Characteristics:
- Sorted Strings Table
- Immutable on disk
- Sorted by key
- Efficient merging
- Cassandra
- LevelDB
- RocksDB
- ✅ Sequential writes
- ✅ Efficient merging
- ❌ Write amplification
- ❌ Read overhead
LSM Tree
LSM Tree
Skiplist + SSTable. High write throughput.Characteristics:
- Log-Structured Merge Tree
- In-memory + on-disk components
- Background compaction
- Write-optimized
- Cassandra
- LevelDB
- RocksDB
- HBase
- ✅ High write throughput
- ✅ Efficient updates
- ❌ Read amplification
- ❌ Compaction overhead
B-tree
B-tree
Disk-based solution. Consistent read/write performance.Characteristics:
- Self-balancing tree
- Multiple keys per node
- Optimized for disk I/O
- Range queries supported
- MySQL (InnoDB)
- PostgreSQL
- Most relational databases
- File systems
- ✅ Balanced read/write
- ✅ Range queries
- ✅ Sorted order
- ❌ Write overhead (rebalancing)
Inverted Index
Inverted Index
Used for document indexing.Characteristics:
- Term → Document mapping
- Full-text search
- Posting lists
- Token-based
- Elasticsearch
- Apache Lucene
- Search engines
- ✅ Fast text search
- ✅ Ranking support
- ❌ Storage overhead
- ❌ Update complexity
Suffix Tree
Suffix Tree
For string pattern search.Characteristics:
- All suffixes indexed
- Pattern matching O(m)
- Space-intensive
- Build time O(n)
- Bioinformatics
- String search algorithms
- Text processing
- ✅ Fast pattern matching
- ✅ Multiple patterns
- ❌ High memory usage
- ❌ Complex implementation
R-tree
R-tree
Multi-dimension search, such as finding the nearest neighbor.Characteristics:
- Spatial indexing
- Bounding boxes (MBR)
- Multi-dimensional data
- Range queries
- PostGIS
- Geospatial databases
- Map applications
- ✅ Spatial queries
- ✅ Nearest neighbor
- ❌ Complex updates
- ❌ Overlap in nodes
B-Tree vs LSM-Tree
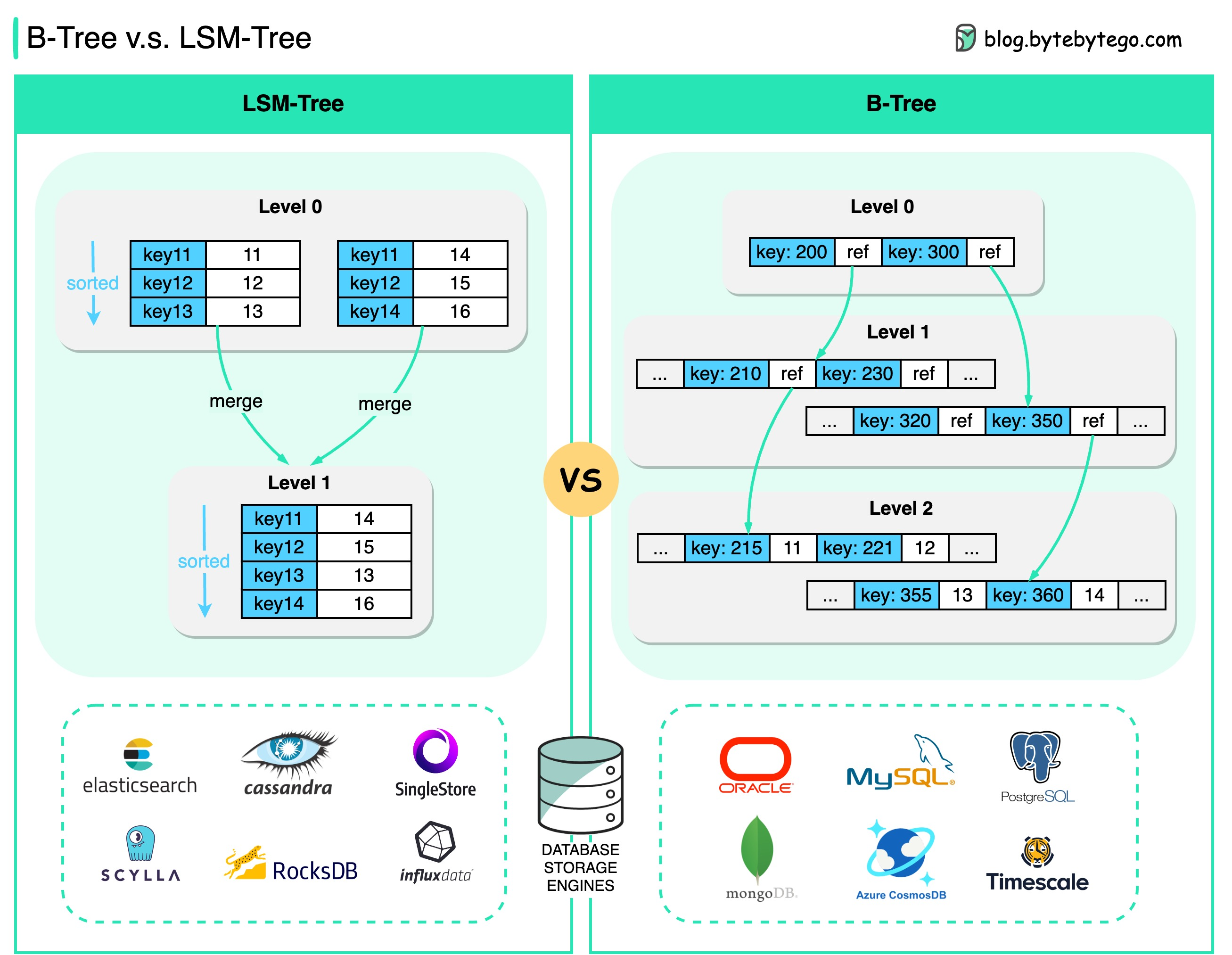 Two of the most important data structures in database design:
Two of the most important data structures in database design:
- B-Tree
- LSM-Tree
- Comparison
Most Widely Used in Relational Databases
B-Tree is the most widely used indexing data structure in almost all relational databases.How it Works:The basic unit of information storage in B-Tree is usually called a “page”. Looking up a key traces down the range of keys until the actual value is found.Characteristics:- Self-balancing tree structure
- Multiple keys per node
- All leaves at same level
- Sorted key order
- Range queries efficient
- Read: O(log n) - Optimized for reads
- Write: O(log n)
- Range query: Efficient
- Point query: Efficient
- Read-heavy workloads
- Range queries
- Transactional databases
- Traditional RDBMS
- MySQL InnoDB
- PostgreSQL
- SQLite
- Most relational databases
Key Algorithms for System Design
 What are some of the algorithms you should know before taking system design interviews?
What are some of the algorithms you should know before taking system design interviews?
Understanding “how those algorithms are used in real-world systems” is generally more important than the implementation details in a system design interview.
Algorithm Importance Levels
- ⭐⭐⭐⭐⭐ Very Important
- ⭐⭐⭐ Important
- ⭐ Advanced
Try to understand how it works and why.
Consistent Hashing
Use Case: Distributed caching, load balancing
- Minimizes reorganization when nodes added/removed
- Used in: Cassandra, DynamoDB, CDNs
- Key concept: Hash ring
Bloom Filter
Use Case: Membership testing, cache optimization
- Space-efficient probabilistic data structure
- False positives possible, no false negatives
- Used in: BigTable, Cassandra, Bitcoin
Merkle Tree
Use Case: Data synchronization, verification
- Efficient comparison of datasets
- Detect inconsistencies
- Used in: Git, Bitcoin, Cassandra
Geohash
Use Case: Location-based services
- Encode lat/long to string
- Proximity search
- Used in: Uber, Google Maps
Data Structure Selection Guide
Quick Reference
Need Fast Lookups?
Need Fast Lookups?
Hash Table / Hash Map
- O(1) average case
- Key-value pairs
- No ordering
- Caching
- Deduplication
- Fast membership testing
- Counting occurrences
Need Ordering?
Need Ordering?
Tree-based structures
- B-Tree: Disk-based, balanced
- BST: In-memory, may be unbalanced
- Red-Black Tree: Self-balancing
- Range queries
- Sorted iteration
- Database indexes
- Priority queues (Heap)
Need Fast Writes?
Need Fast Writes?
LSM-Tree or Log-based
- Append-only writes
- Background compaction
- Write-optimized
- Time-series data
- Logging systems
- Write-heavy workloads
- Event sourcing
Need Spatial Queries?
Need Spatial Queries?
R-Tree or QuadTree
- Multi-dimensional indexing
- Bounding boxes
- Nearest neighbor
- Geospatial applications
- Location-based services
- Map applications
- Collision detection
Need Text Search?
Need Text Search?
Inverted Index or Trie
- Term-based indexing
- Full-text search
- Prefix matching
- Search engines
- Autocomplete
- Document search
- Log analysis
Need Graph Relationships?
Need Graph Relationships?
Graph structures
- Adjacency list
- Adjacency matrix
- Graph databases
- Social networks
- Recommendation engines
- Path finding
- Dependency resolution
Time Complexity Cheat Sheet
Common Data Structure Operations
| Data Structure | Access | Search | Insert | Delete | Space |
|---|---|---|---|---|---|
| Array | O(1) | O(n) | O(n) | O(n) | O(n) |
| Linked List | O(n) | O(n) | O(1) | O(1) | O(n) |
| Hash Table | - | O(1)* | O(1)* | O(1)* | O(n) |
| Binary Search Tree | O(log n)* | O(log n)* | O(log n)* | O(log n)* | O(n) |
| B-Tree | O(log n) | O(log n) | O(log n) | O(log n) | O(n) |
| Skip List | O(log n) | O(log n) | O(log n) | O(log n) | O(n log n) |
| Heap | - | O(n) | O(log n) | O(log n) | O(n) |
- Average case. Worst case may differ.
Interview Tips
Key Questions to Ask
Access Patterns
- What’s the read/write ratio?
- Are range queries needed?
- Is ordering important?
- What’s the query latency requirement?
Scale Considerations
- What’s the data volume?
- How fast is it growing?
- How many concurrent users?
- What’s the throughput requirement?
Performance Requirements
- What’s acceptable latency?
- Is consistency critical?
- Can we tolerate eventual consistency?
- What about durability?
Operational Concerns
- What’s the maintenance overhead?
- How do we handle compaction?
- What about memory usage?
- Is the structure disk-friendly?
Practice Problems
Design a Cache System
Design a Cache System
Consider:
- Hash table for O(1) lookups
- Doubly linked list for LRU eviction
- Combined: LRU Cache
- Memory overhead for linked list
- Fast reads and updates
- Eviction policy implementation
Design a Real-time Leaderboard
Design a Real-time Leaderboard
Consider:
- Sorted Set (Skip List) for ranking
- Hash table for user scores
- Redis sorted sets
- Memory for maintaining order
- Fast score updates
- Efficient range queries for top N
Design a Geospatial Index
Design a Geospatial Index
Consider:
- QuadTree for 2D partitioning
- Geohash for encoding
- R-Tree for bounding boxes
- Balance between precision and performance
- Update complexity
- Query efficiency
Design a Search Engine
Design a Search Engine
Consider:
- Inverted index for terms
- Trie for autocomplete
- Ranking algorithms
- Storage overhead
- Index update latency
- Query performance
Summary
Know the Basics
Master fundamental data structures: arrays, lists, hash tables, trees, graphs.
Understand Trade-offs
Every data structure has pros and cons. Know when to use which.
Think Real-World
Connect data structures to actual systems: how does Redis use skip lists?
Consider Scale
What works for 1000 items may not work for 1 billion.
Analyze Complexity
Always discuss time and space complexity of your choices.
Practice
Work through real system design problems using different data structures.