Multi-User Support
Memori provides built-in multi-user and multi-process isolation through its attribution system. Each combination of entity, process, and session creates an isolated memory space — user A never sees user B’s memories, and your support bot has different context than your sales bot.
Isolation Model
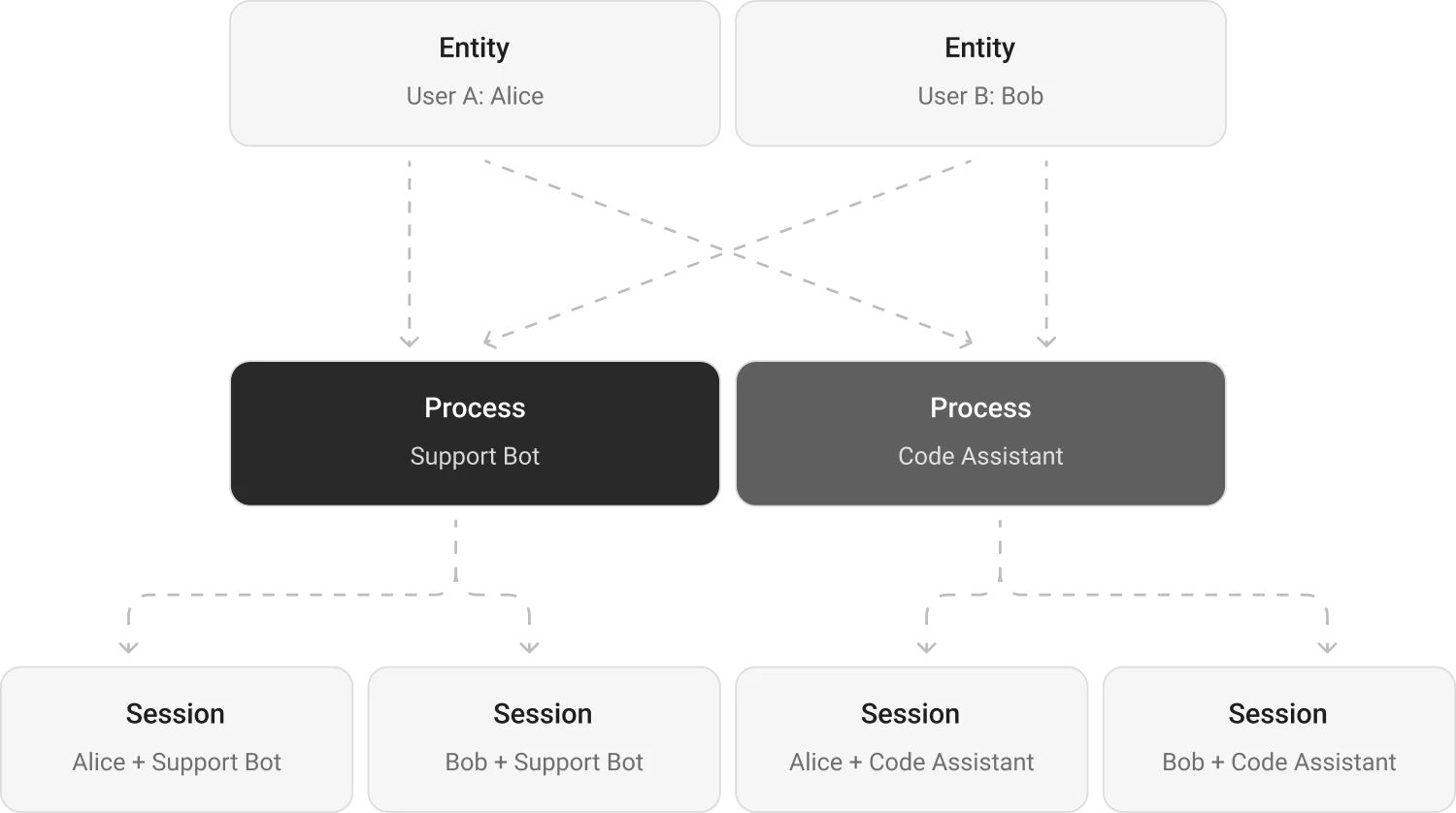
What’s Shared vs Isolated
| Data | Scope |
|---|
| Facts | Per entity — shared across all processes |
| Preferences | Per entity |
| Skills | Per entity |
| Attributes | Per process |
| Conversations | Per entity + process + session |
| Sessions | Per entity + process (auto-generated UUID) |
| Knowledge Graph | Per entity |
Entity Attribution
Entities represent the who in your application — typically users, but can also be organizations, teams, or any other identity.
from memori import Memori
from openai import OpenAI
client = OpenAI()
mem = Memori().llm.register(client)
# User A's conversations
mem.attribution(entity_id="user_alice", process_id="support_bot")
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "I prefer dark mode"}]
)
# User B's conversations — completely isolated
mem.attribution(entity_id="user_bob", process_id="support_bot")
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "What are my preferences?"}]
)
# Bob will NOT see Alice's preferences
Entity ID Constraints
- Type: String (converted via
str(entity_id))
- Max length: 100 characters
- Validation: Enforced in
memori/__init__.py:122-127
# Valid entity IDs
mem.attribution(entity_id="user_123", process_id="bot")
mem.attribution(entity_id="org_acme", process_id="analytics")
mem.attribution(entity_id=12345, process_id="bot") # Converted to "12345"
# Invalid: exceeds 100 characters
mem.attribution(entity_id="a" * 101, process_id="bot")
# Raises: RuntimeError
Process Attribution
Processes represent the what — the agent, bot, or workflow creating memories.
from memori import Memori
from openai import OpenAI
client = OpenAI()
mem = Memori().llm.register(client)
# Same user, different processes
mem.attribution(entity_id="user_alice", process_id="support_bot")
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": "I use PostgreSQL for my databases"}
]
)
# Switch to a different process for the same user
mem.attribution(entity_id="user_alice", process_id="sales_bot")
# The sales bot can recall Alice's facts (like "uses PostgreSQL")
# because facts are shared across processes for the same entity.
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": "What databases do I use?"}
]
)
Process ID Constraints
- Type: String (converted via
str(process_id))
- Max length: 100 characters
- Validation: Enforced in
memori/__init__.py:129-133
Session Management
Sessions group related conversations together. Each session has a unique UUID and a timeout (default: 30 minutes).
from memori import Memori
from openai import OpenAI
client = OpenAI()
mem = Memori().llm.register(client)
mem.attribution(entity_id="user_alice", process_id="support_bot")
# Get the current session ID
current_session = mem.config.session_id
print(f"Session: {current_session}")
# Output: Session: UUID('...')
# Start a new conversation group
mem.new_session()
print(f"New session: {mem.config.session_id}")
# Or restore a previous session
mem.set_session(current_session)
print(f"Restored session: {mem.config.session_id}")
Session Timeout
Sessions automatically expire after 30 minutes of inactivity (configurable):
mem.config.session_timeout_minutes = 60 # 1 hour timeout
memori/_config.py:84
Common Patterns
Web Application
Set the entity ID from the authenticated user. Works with Flask, FastAPI, Django, or any web framework.
from memori import Memori
from openai import OpenAI
from fastapi import FastAPI, Depends
from fastapi.security import HTTPBearer
app = FastAPI()
security = HTTPBearer()
def get_user_id(token: str = Depends(security)) -> str:
# Validate token and extract user ID
return "user_123" # Replace with actual logic
@app.post("/chat")
async def chat(message: str, user_id: str = Depends(get_user_id)):
client = OpenAI()
mem = Memori().llm.register(client)
mem.attribution(entity_id=user_id, process_id="web_assistant")
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": message}]
)
return {"response": response.choices[0].message.content}
Multi-Agent System
Give each agent a unique process ID. Facts are shared across agents for the same entity, but each agent maintains its own conversation history.
from memori import Memori
from openai import OpenAI
def create_agent(user_id: str, agent_name: str):
client = OpenAI()
mem = Memori().llm.register(client)
mem.attribution(entity_id=user_id, process_id=agent_name)
return client
# Three agents, one user, shared facts
support = create_agent("user_alice", "support_agent")
sales = create_agent("user_alice", "sales_agent")
onboard = create_agent("user_alice", "onboarding_agent")
# Support agent conversation
response = support.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "I use PostgreSQL"}]
)
# Sales agent can access the same fact
response = sales.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "What database do I use?"}]
)
# AI knows: PostgreSQL (from support agent conversation)
Organizational Hierarchy
Use entity IDs to represent different levels:
# User-level memory
mem.attribution(entity_id="user_alice", process_id="bot")
# Team-level memory (shared across team members)
mem.attribution(entity_id="team_engineering", process_id="bot")
# Organization-level memory (shared across entire org)
mem.attribution(entity_id="org_acme", process_id="bot")
Multi-Tenancy
Isolate memories by tenant:
def handle_chat(tenant_id: str, user_id: str, message: str):
# Combine tenant and user for complete isolation
entity_id = f"{tenant_id}:{user_id}"
mem = Memori()
mem.attribution(entity_id=entity_id, process_id="assistant")
# Tenant A's user_123 is isolated from Tenant B's user_123
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": message}]
)
return response.choices[0].message.content
Attribution Caching
Memori caches resolved entity, process, and session IDs to avoid repeated database lookups:
# First call resolves and caches IDs
mem.attribution(entity_id="user_alice", process_id="bot")
response = client.chat.completions.create(...)
# Cache stores: entity_id, process_id, session_id, conversation_id
# Subsequent calls reuse cached IDs (fast)
response = client.chat.completions.create(...)
# Cache is reset on new session
mem.new_session() # Clears conversation_id from cache
memori/_config.py:41-46 and usage in memori/memory/_manager.py:76-111
Attribution Resolution
When you set attribution, Memori resolves the external IDs to internal database IDs:
- Entity lookup: Check if
"user_alice" exists in memori_entity table
- Entity creation: If not found, insert new row and return ID
- Process lookup: Check if
"support_bot" exists in memori_process table
- Process creation: If not found, insert new row and return ID
- Session creation: Create new session linking entity and process
- Conversation creation: Create new conversation within the session
All of this happens transparently on the first LLM call.
Source: Entity resolution in memori/memory/recall.py:41-53
Memory Isolation Guarantees
Entity Isolation
- Facts: User A cannot recall User B’s facts
- Knowledge graph: User A’s graph is separate from User B’s graph
- Conversations: User A never sees User B’s conversation history
Process Isolation
- Attributes: Process A’s attributes are separate from Process B’s attributes
- Conversations: Process A’s conversation history is separate from Process B’s
- Facts: Shared across processes for the same entity
Session Isolation
- Conversations: Session 1 conversations are separate from Session 2
- Context: Each session maintains its own conversation context
- Facts: Accumulated across all sessions for an entity
Handling Anonymous Users
For anonymous or unauthenticated users, generate a unique identifier:
import uuid
# Generate unique ID for anonymous user
anonymous_id = f"anon_{uuid.uuid4()}"
mem = Memori()
mem.attribution(entity_id=anonymous_id, process_id="public_bot")
# Later, if user authenticates, migrate memories:
# (requires custom implementation)
def migrate_memories(from_entity_id: str, to_entity_id: str):
# Update memori_entity_fact.entity_id
# Update memori_knowledge_graph.entity_id
# Update memori_session.entity_id
pass
Memori doesn’t provide built-in memory migration. If you need to transfer memories from an anonymous user to an authenticated user, you’ll need to implement custom database updates.
Dynamic Attribution
You can change attribution mid-session:
mem = Memori().llm.register(client)
# Start with one user
mem.attribution(entity_id="user_alice", process_id="bot")
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "I like Python"}]
)
# Switch to another user
mem.attribution(entity_id="user_bob", process_id="bot")
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "I like JavaScript"}]
)
# Each user's memories are isolated
Be careful when changing attribution mid-session. The cache is updated immediately, so subsequent LLM calls use the new attribution. If you need to maintain separate conversations, create separate Memori instances.
Attribution Chaining
The attribution() method returns self, allowing for method chaining:
mem = Memori().llm.register(client).attribution(
entity_id="user_alice",
process_id="support_bot"
)
# Or step by step
mem = Memori()
mem.llm.register(client)
mem.attribution(entity_id="user_alice", process_id="support_bot")
memori/__init__.py:122-138
Testing Multi-User Scenarios
When writing tests, ensure proper isolation:
import pytest
from memori import Memori
from openai import OpenAI
def test_user_isolation():
client = OpenAI()
mem = Memori().llm.register(client)
# User A stores a preference
mem.attribution(entity_id="user_a", process_id="test_bot")
client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "I prefer dark mode"}]
)
mem.augmentation.wait() # Wait for augmentation
# User B should not see User A's preference
mem.attribution(entity_id="user_b", process_id="test_bot")
facts = mem.recall("mode preferences", limit=10)
# Assert User B has no facts about dark mode
assert not any("dark mode" in fact.content for fact in facts)