Overview
Discord has become one of the world’s most popular communication platforms, serving millions of concurrent users across gaming communities, educational groups, and professional workspaces. The platform’s success relies on its ability to deliver messages instantly while storing and retrieving billions of conversations reliably. This case study explores Discord’s remarkable database evolution journey, demonstrating how architectural decisions must adapt as systems scale from thousands to trillions of messages.The Challenge: Storing Trillions of Messages
Discord faces unique challenges in message storage:Massive Scale
- Trillions of messages stored
- Billions of new messages daily
- Growing exponentially
- Must retain indefinitely
Performance Requirements
- Real-time message delivery
- Fast historical message retrieval
- Low latency for search
- High availability (99.99%+)
Access Patterns
- Recent messages accessed frequently
- Older messages rarely accessed
- Bursty traffic patterns
- Hot channels vs. quiet channels
Operational Concerns
- Minimal downtime for maintenance
- Predictable performance
- Cost-effective storage
- Easy operational management
The Evolution Journey
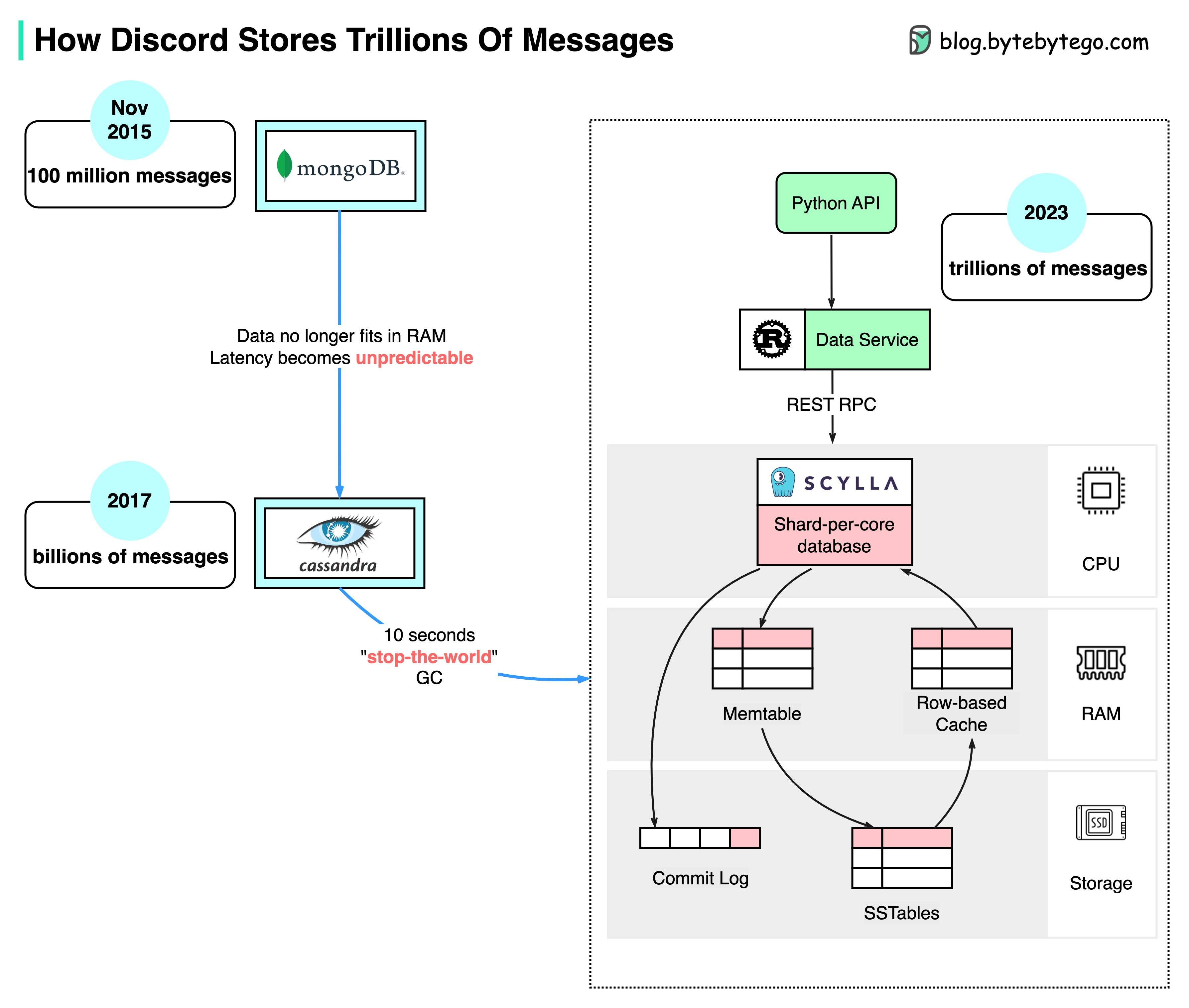
Stage 1: MongoDB (2015)
The Beginning
When Discord launched in 2015, the first version was built on a single MongoDB replica set.Why MongoDB?
Why MongoDB?
Advantages for Early Stage:
- Quick to set up and get started
- Flexible schema for rapid iteration
- Built-in replication
- Good documentation and community
- Document model fit message structure
- Single replica set (primary + secondaries)
- One collection for messages
- Indexed by channel ID and timestamp
- Simple backup strategy
The Problems
Breaking Point: ~100 Million Messages (November 2015) After just a few months of growth, critical issues emerged:Memory Exhaustion
The Issue:
- MongoDB relies on RAM for indexes
- Working set exceeded available memory
- Data and indexes couldn’t fit in RAM
- Frequent disk reads
- Performance degradation
- Unpredictable latency
Unpredictable Latency
The Issue:
- Latency spikes during peak hours
- Some queries taking seconds
- Cache thrashing
- Poor user experience
- Message delays
- Service instability
Stage 2: Cassandra (2015-2022)
The Migration
Discord chose Apache Cassandra for its next-generation message storage.Why Cassandra?
Why Cassandra?
Key Advantages:Horizontal Scalability:
- Distributed architecture
- Add nodes to increase capacity
- No single point of failure
- Linear scalability
- Optimized for high write throughput
- LSM tree data structure
- Writes are sequential on disk
- Perfect for append-heavy workload
- Replication across nodes
- Configurable consistency
- Automatic failure handling
- Multi-datacenter support
- Wide-column store
- Natural fit for time-series data
- Partition by channel ID
- Sort by message timestamp
Data Model Design
Table Schema:- Partition Key:
channel_id(distributes data across cluster) - Clustering Key:
message_id(sorts messages within partition) - Descending Order: Most recent messages retrieved first
- Denormalization: Accept data duplication for query performance
Early Success (2017)
By 2017:- 12 Cassandra nodes
- Billions of messages stored
- Stable, predictable performance
- Linear scalability confirmed
- Happy operations team
Growing Pains (2022)
By early 2022, Discord had grown massively: Scale:- 177 Cassandra nodes
- Trillions of messages
- Massive operational complexity
1. Unpredictable Latency
1. Unpredictable Latency
Symptoms:
- P99 latency spikes
- Occasional slow queries
- Inconsistent performance
- LSM trees optimize for writes
- Reads must check multiple SSTables
- Compaction overhead
- Read path more expensive than writes
- Popular channels = hot partitions
- Hundreds of concurrent users
- Single node handling hot partition
- Uneven load distribution
- Messages sometimes delayed
- User complaints
- Poor experience in busy channels
2. Maintenance Operations
2. Maintenance Operations
Challenges:Compaction:
- Merges SSTables to reduce read amplification
- CPU and I/O intensive
- Impacts foreground query performance
- Must run regularly
- Difficult to schedule
- Ensures replica consistency
- Extremely resource intensive at scale
- Takes days to complete
- Risks affecting production traffic
- Streaming data to new nodes
- Hours or days to complete
- Network bottleneck
- Operational risk
- High operational burden
- Risk of performance degradation
- Difficult capacity planning
3. Garbage Collection Pauses
3. Garbage Collection Pauses
The Problem:
- Cassandra written in Java
- JVM garbage collection
- GC pauses can be hundreds of milliseconds
- Stop-the-world events
- Latency spikes during GC
- Unpredictable performance
- Difficult to tune
- Affects all queries during GC
- Real-time chat requires consistency
- GC pauses noticeable to users
- Harder to optimize as data grows
Stage 3: ScyllaDB (2022-Present)
The Solution
Discord migrated to ScyllaDB, a Cassandra-compatible database written in C++.What is ScyllaDB?
What is ScyllaDB?
Overview:
- Drop-in replacement for Cassandra
- Compatible with Cassandra Query Language (CQL)
- Same data model and concepts
- Rewritten from scratch in C++
- Remove JVM bottlenecks
- Better CPU utilization
- Predictable latency
- Higher throughput
- Not just faster Cassandra
- Fundamentally different internals
- Thread-per-core architecture
- Custom async framework
Technical Advantages
No Garbage Collection
C++ Memory Management:
- No GC pauses
- Predictable performance
- Manual memory control
- Consistent latency
Thread-Per-Core
Architecture:
- One thread per CPU core
- No context switching
- Lock-free data structures
- Better CPU cache usage
Better Compaction
Improvements:
- More efficient algorithms
- Less impact on queries
- Smarter scheduling
- Reduced overhead
Auto-Tuning
Smart Defaults:
- Automatic resource management
- Self-optimizing
- Less manual tuning
- Adapts to workload
Performance Improvements
Dramatic Latency Reduction: ScyllaDB delivered 3-8x better latency compared to Cassandra for Discord’s workload.
- Cassandra P99: 40-125ms
- ScyllaDB P99: 15ms
- Improvement: Up to 8x faster
- Cassandra P99: 5-70ms
- ScyllaDB P99: 5ms
- Improvement: More consistent, up to 14x faster
- More predictable performance
- Fewer outliers
- Lower P999 latency
- Better tail latencies
Architectural Redesign
Discord didn’t just swap databases - they redesigned their architecture:New Architecture Components
New Architecture Components
1. Monolithic API:
- Consolidated multiple APIs
- Simplified request routing
- Reduced network hops
- Easier to maintain
- Written in Rust for performance
- Handles all database interactions
- Caching layer
- Connection pooling
- Query optimization
- Primary message store
- Same data model as Cassandra
- Improved performance
- Better operational characteristics
- Clear separation of concerns
- Optimized data access layer
- Better caching strategies
- Reduced latency
Migration Strategy
How They Did It:Dual-Write Approach
Dual-Write Approach
Phase 1: Preparation
- Set up ScyllaDB cluster
- Replicate schema
- Test thoroughly
- Performance benchmarking
- Write to both Cassandra and ScyllaDB
- Read from Cassandra (existing behavior)
- Monitor for inconsistencies
- Verify ScyllaDB performance
- Copy historical data to ScyllaDB
- Verify data integrity
- Check partition consistency
- Performance testing with real data
- Start reading from ScyllaDB (small %)
- Monitor metrics carefully
- Gradually increase percentage
- Rollback capability at each step
- 100% reads from ScyllaDB
- Stop writes to Cassandra
- Keep Cassandra as backup (initially)
- Monitor for issues
- After confidence period
- Remove Cassandra cluster
- Complete migration
Key Architectural Patterns
1. Time-Series Data Model
Messages are inherently time-series data: Characteristics:- Append-only writes
- Recent data accessed most
- Partitioned by entity (channel)
- Sorted by time
- Partition by channel_id
- Cluster by message_id (timestamp-based)
- Descending order for recent-first access
- TTL for very old data (if needed)
2. Hot Partition Management
The Problem:- Popular channels = hot partitions
- Single partition can’t scale beyond one node
- Bottleneck for busy channels
Read Replicas
Read Replicas
- Multiple replicas serve reads
- Distribute read load
- Eventual consistency acceptable
- Reduces hot partition impact
Caching Layer
Caching Layer
- Cache hot channel data
- Reduce database queries
- Redis/Memcached layer
- Warm cache for popular channels
Connection Pooling
Connection Pooling
- Limit concurrent requests
- Queue excess requests
- Prevent database overload
- Graceful degradation
3. Operational Efficiency
Automation:- Automated repairs and compaction
- Self-healing capabilities
- Monitoring and alerting
- Capacity planning tools
- Per-node metrics
- Query performance tracking
- Compaction monitoring
- Resource utilization
Lessons Learned
Core Lesson: No database is perfect forever. As your scale and requirements change, be willing to re-evaluate foundational technology choices.
Key Takeaways
1. Right Tool for Right Scale:- MongoDB: Great for 0-100M messages
- Cassandra: Perfect for 100M-100B messages
- ScyllaDB: Best for 100B+ messages
- Different databases excel at different scales
- LSM trees (Cassandra/ScyllaDB) optimize writes
- Read-heavy workloads need special consideration
- Caching becomes more important
- Monitor read amplification
- JVM GC pauses are real
- C++ can offer significant performance benefits
- Memory management affects predictability
- Consider runtime characteristics at scale
- More nodes = more complexity
- Maintenance operations become critical
- Automation is essential
- Consider operational burden in database choice
- ScyllaDB’s Cassandra compatibility was crucial
- Drop-in replacement reduced migration risk
- Same queries, same data model
- Incremental migration possible
- Detailed metrics enabled informed decisions
- Performance benchmarking crucial
- Real-world testing before migration
- Continuous monitoring post-migration
Performance Comparison
Latency Comparison
| Metric | MongoDB (2015) | Cassandra (2022) | ScyllaDB (2022) |
|---|---|---|---|
| Messages Stored | 100M | Trillions | Trillions |
| Nodes | 1 replica set | 177 nodes | ~fewer nodes |
| P99 Read | Seconds+ | 40-125ms | 15ms |
| P99 Write | Varies | 5-70ms | 5ms |
| GC Pauses | Yes | Yes (major issue) | No |
| Compaction Impact | N/A | High | Low |
Cost Comparison
Infrastructure Savings:- Fewer nodes needed for same performance
- Better resource utilization
- Reduced operational overhead
- Lower maintenance costs
Technical Deep Dive: Why ScyllaDB is Faster
Thread-Per-Core Architecture
Traditional Approach (Cassandra):- Shared-nothing thread pools
- Context switching overhead
- Lock contention
- Cache line bouncing
- One shard per CPU core
- Each shard is independent
- No locks needed
- Better CPU cache utilization
Async Programming Model
Seastar Framework:- Custom C++ async framework
- Futures and promises
- Non-blocking I/O
- Efficient task scheduling
- Maximum CPU utilization
- Lower latency
- Higher throughput
- Better resource efficiency
Compaction Improvements
Smarter Scheduling:- Compaction runs when resources available
- Less impact on foreground queries
- Adaptive algorithms
- Better space amplification management
- Smaller compaction batches
- More frequent but lighter
- Reduced latency spikes
- Predictable performance
Current Architecture
Message Pipeline:- Client sends message → Gateway
- Gateway → Monolithic API
- API → Data Service (Rust)
- Data Service → ScyllaDB
- ScyllaDB → Replicates to 3 nodes
- Async: Fanout to online users via WebSockets
- Client requests history → Gateway
- Gateway → Monolithic API
- API → Data Service (Rust)
- Data Service → Check cache
- If miss → Query ScyllaDB
- ScyllaDB → Return messages
- Data Service → Update cache
- Return → Client
Scale Statistics
- Trillions of messages stored
- Billions of messages per day
- Millions of concurrent users
- 177 nodes (Cassandra) → fewer nodes (ScyllaDB)
- 15ms P99 read latency
- 5ms P99 write latency
- 3-8x performance improvement