Overview
Twitter (now X) is one of the most influential social media platforms, enabling real-time communication and information sharing across the globe. With over 400 million monthly active users posting hundreds of millions of tweets daily, Twitter’s architecture has evolved significantly to handle massive scale while maintaining real-time performance. This case study examines Twitter’s technical evolution, architecture patterns, and the sophisticated systems powering the “For You” timeline.Architecture Evolution: 2012 vs 2022
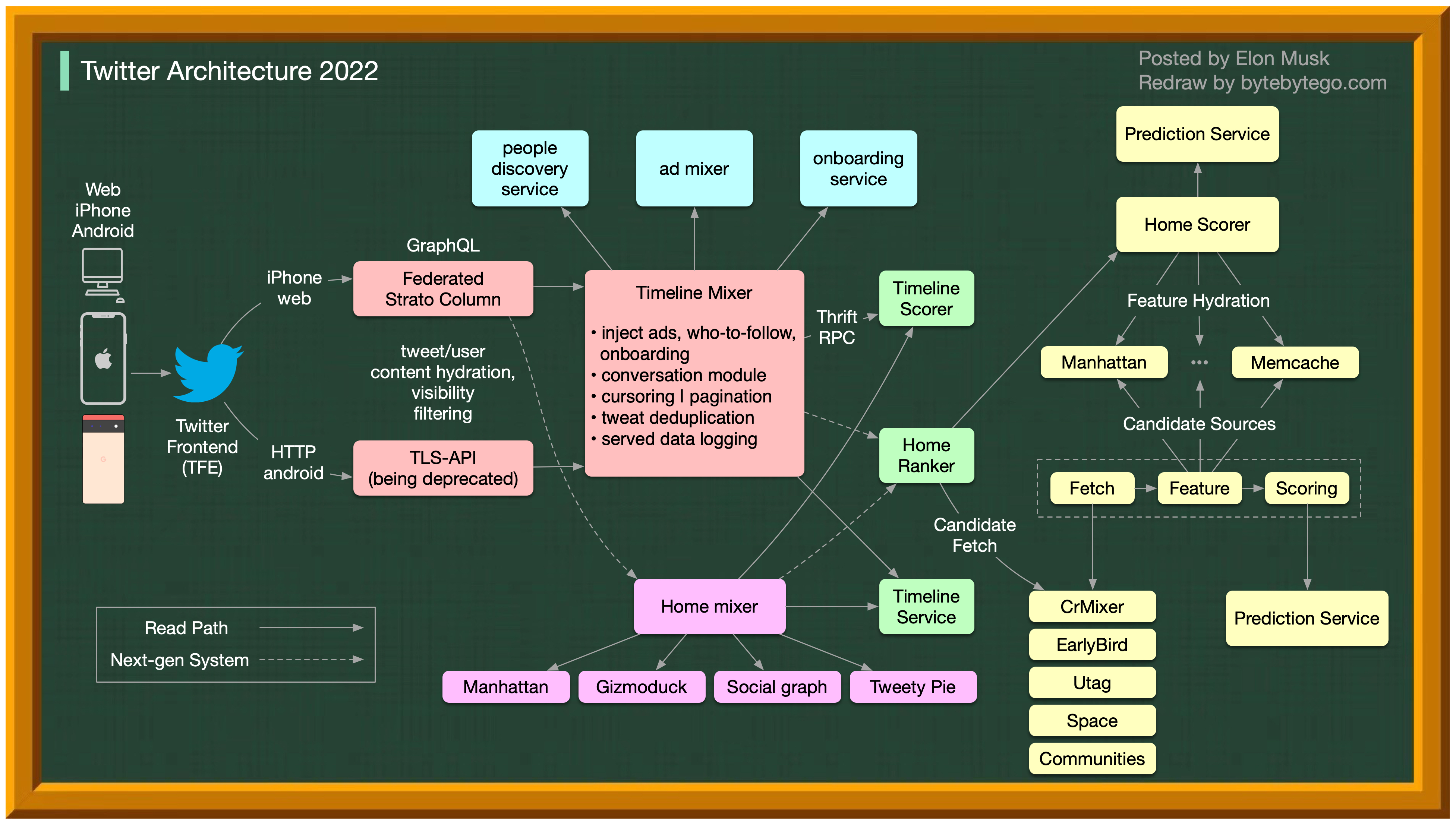 Over the past decade, Twitter’s architecture has undergone dramatic transformation to support increased scale, new features, and better user experience.
Over the past decade, Twitter’s architecture has undergone dramatic transformation to support increased scale, new features, and better user experience.
Key Changes
Scale Growth
- 10x increase in users
- 100x increase in tweets
- Global distribution
- Multi-region deployment
Technology Evolution
- Monolith to microservices
- Custom infrastructure
- ML-powered recommendations
- Real-time processing at scale
Twitter 1.0 Tech Stack
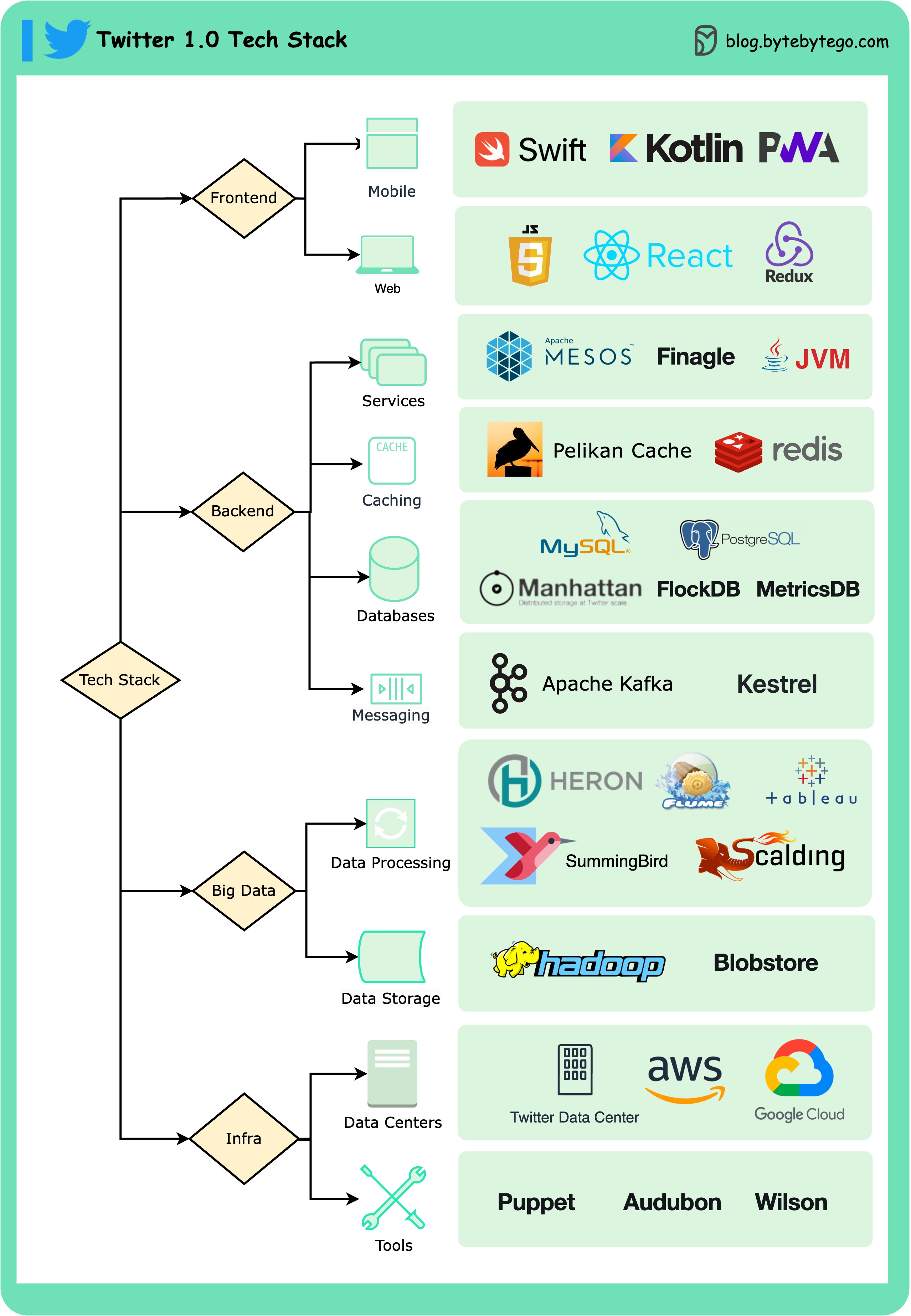
Frontend Technologies
Mobile Applications
Mobile Applications
iOS:
- Swift: Native iOS development
- Platform-specific optimizations
- Offline capabilities
- Kotlin: Modern Android development
- Material Design guidelines
- Performance optimizations
- Web-based mobile experience
- Reduced data usage
- Faster initial load
Web Application
Web Application
Technology Stack:
- JavaScript/TypeScript: Core language
- React: UI framework
- Redux: State management
- Component-based design
- Server-side rendering
- Code splitting for performance
- Progressive enhancement
Backend Services
Service Infrastructure
Service Infrastructure
Apache Mesos:
- Cluster management
- Resource allocation
- Service orchestration
- Multi-tenant infrastructure
- RPC framework (built by Twitter)
- Protocol-agnostic
- Async, concurrent programming model
- Circuit breakers and retry logic
- Service discovery integration
- Fault tolerant
- Load balancing
- Connection pooling
- Observability built-in
Caching Layer
Pelikan Cache
Twitter’s custom caching solution:
- Built in C for performance
- Low memory overhead
- High throughput
- Memcached and Redis compatible
Redis
Used for:
- Session storage
- Real-time counters
- Leaderboards
- Timeline caching
Database Architecture
Manhattan - Distributed Database
Manhattan - Distributed Database
Twitter’s custom distributed database:Architecture:
- AP system (Available and Partition-tolerant)
- Eventually consistent
- Multi-datacenter replication
- User profiles
- Tweet storage
- Social graph
- Timeline data
- Horizontal scalability
- Multi-tenancy
- Automated sharding
- Hot data rebalancing
MySQL
MySQL
Used for:
- Transactional data
- User authentication
- Billing and payments
- Strongly consistent data
- Horizontally partitioned
- ID-based sharding
- Cross-shard queries minimized
PostgreSQL
PostgreSQL
Used for:
- Analytics workloads
- Complex queries
- Reporting systems
- Internal tools
Recommendation System: “For You” Timeline
Twitter can recommend relevant tweets and build a personalized “For You” timeline in just 1.5 seconds - processing 500 million potential tweets down to the final feed.
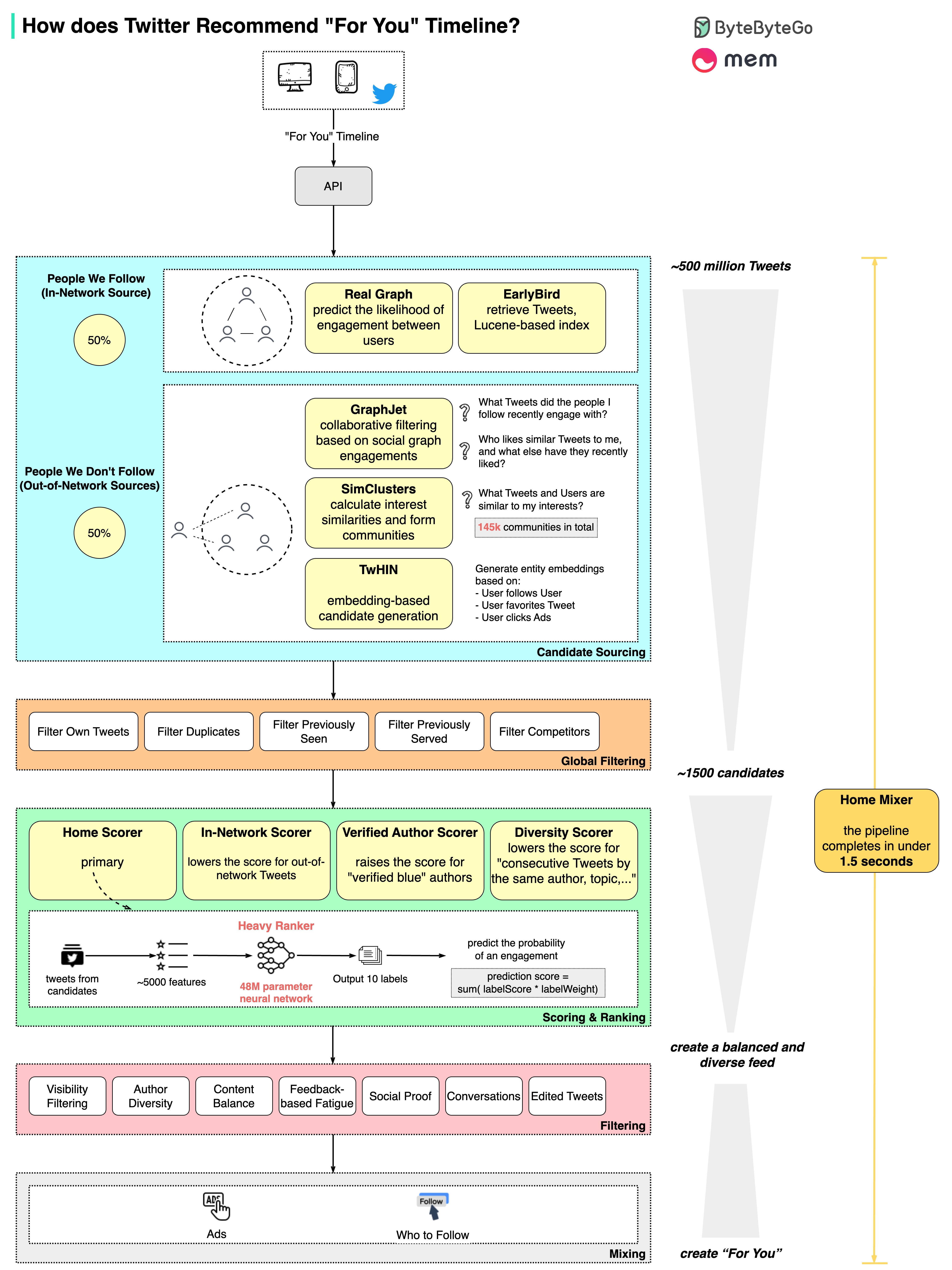
The Five-Stage Pipeline
Twitter’s recommendation system is one of the most sophisticated in the industry, involving multiple stages to deliver personalized content:Stage 1: Candidate Sourcing
Starting Point: ~500 million tweetsCandidate Sources
Candidate Sources
In-Network Sources:
- Tweets from users you follow
- Recent tweets (recency-based ranking)
- Popular tweets from your network
- Tweets from similar users
- Trending topics
- Collaborative filtering
- Content-based recommendations
- User embeddings
- Tweet embeddings
- Cosine similarity search
- Vector databases (Faiss)
Stage 2: Global Filtering
Result: ~1,500 candidates Filters Applied:- Remove blocked/muted users
- Filter out tweets you’ve seen
- Remove tweets that violate policies
- Deduplicate similar content
- Age filter (too old tweets removed)
- NSFW filtering based on settings
- Must process 500M tweets quickly
- Distributed filtering across clusters
- Cached filter results
Stage 3: Scoring and Ranking
The Core Ranking Model:Neural Network Architecture
Neural Network Architecture
Model Size: 48 million parametersInput Features:
- User features (1000+ dimensions)
- Follow graph
- Engagement history
- Demographics
- Interests
- Tweet features (500+ dimensions)
- Content embeddings
- Author information
- Engagement metrics
- Freshness
- Context features
- Time of day
- Device type
- Location
- Probability of engagement (like, retweet, reply)
- Dwell time
- Negative actions (report, mute, block)
- Follow probability
- Trained on billions of examples
- Multi-task learning
- Regular retraining (daily)
- A/B testing for improvements
Ranking Signals
Ranking Signals
Engagement Predictions:
- Like probability (weight: 1x)
- Retweet probability (weight: 2x)
- Reply probability (weight: 3x)
- Profile click probability
- Video watch time
- Author authority
- Tweet freshness
- Media richness (images/videos)
- Link quality
- Historical interactions
- Topic interests
- Network similarity
- Explicit feedback
Twitter Blue Boost
Twitter Blue Boost
Subscribers to Twitter Blue receive ranking boosts:Boosting Strategy:
- 2x boost for verified subscribers
- Applied after scoring
- Helps surface quality content
- Controversial but revenue-driven
- Multiplicative boost to score
- Configurable weight
- A/B tested extensively
Stage 4: Filtering for Diversity
Goal: Achieve author and content diversityDiversity Rules
Diversity Rules
Author Diversity:
- Limit tweets from same author
- Space out tweets from followed accounts
- Mix in-network and out-of-network
- Avoid similar topics in sequence
- Mix media types (text, images, videos)
- Balance trending vs evergreen content
- Mix recent and older tweets
- Balance real-time and algorithmic content
- Ensure some recency
- Sliding window deduplication
- Topic clustering
- Greedy selection with constraints
- Re-ranking for diversity
Stage 5: Mixing with Other Content
Final Timeline Composition:Recommended Tweets
70-80% of timeline
Advertisements
10-15% of timeline
Who to Follow
5-10% of timeline
- Interleave ads at optimal frequency
- Insert “Who to Follow” suggestions
- Add trending topics
- Include promoted content
- Balance monetization and user experience
Performance Optimization
To achieve the 1.5-second goal: Parallelization:- Stages run in parallel where possible
- Distributed scoring across GPU clusters
- Asynchronous processing
- User embeddings cached
- Tweet features pre-computed
- Popular tweets pre-ranked
- Low-latency data stores
- Edge computing for regional users
- Predictive pre-fetching
Real-Time Tweet Delivery
Fanout Architecture
When a user posts a tweet: Fanout-on-Write (for small followings):- Tweet posted to database
- Immediately pushed to followers’ timelines
- Cached in Redis/Pelikan
- Fast reads at the cost of write amplification
- Tweet posted to database
- Followers fetch dynamically when reading timeline
- Reduces write amplification
- Used for celebrities with millions of followers
- Small/medium accounts: fanout-on-write
- Large accounts: fanout-on-read
- Threshold-based decision
- Optimizes for both read and write performance
Streaming and Messaging
Apache Kafka
Twitter heavily uses Kafka for: Use Cases:- Tweet stream processing
- Real-time analytics
- Event sourcing
- Cross-datacenter replication
- Feed generation
- Billions of messages daily
- Hundreds of clusters
- Petabytes of data
- Sub-second latency
Stream Processing
Apache Storm / Heron:- Real-time computation
- Trend detection
- Spam filtering
- Real-time counters
- Event time processing
- Windowed aggregations
- Stateful processing
- Exactly-once semantics
Key Architecture Decisions
1. Custom Infrastructure
Twitter built many custom solutions:- Manhattan: Distributed database
- Pelikan: High-performance cache
- Finagle: RPC framework
- Heron: Stream processing (Storm successor)
- Specific performance requirements
- Scale beyond existing solutions
- Optimize for Twitter’s access patterns
- Full control over performance tuning
2. Hybrid Fanout Strategy
- Balances read and write performance
- Handles both typical and celebrity users
- Reduces infrastructure costs
- Maintains real-time experience
3. Machine Learning at Scale
- 48M parameter ranking model
- Billions of training examples
- Real-time inference
- Continuous learning and improvement
4. Multi-Datacenter Architecture
- Active-active across regions
- Eventually consistent model
- Optimized for availability
- Graceful degradation
Challenges and Solutions
Hot Partitions
Problem: Celebrity tweets cause traffic spikesSolution:
- Fanout-on-read for large accounts
- Dynamic traffic routing
- Read replicas for hot data
Real-Time Ranking
Problem: Rank 500M tweets in 1.5sSolution:
- Multi-stage filtering
- GPU acceleration for scoring
- Pre-computed features
- Aggressive caching
Spam and Abuse
Problem: Malicious content at scaleSolution:
- ML-based spam detection
- Real-time filtering
- User reporting signals
- Automated enforcement
Timeline Freshness
Problem: Balance real-time and algorithmicSolution:
- Hybrid timeline approach
- User controls for chronological
- Freshness as ranking signal
- Real-time tweet insertion
Lessons Learned
Key Takeaway: Twitter’s architecture demonstrates that building custom infrastructure can be justified at massive scale when existing solutions don’t meet specific requirements.
- Twitter built custom solutions (Manhattan, Pelikan, Finagle) when needed
- Used open-source where appropriate (Kafka, Mesos)
- Balance between build and buy
- Multiple stages of filtering/ranking
- Parallelization and caching critical
- GPU acceleration for ML inference
- Sacrifice perfect consistency for availability
- Massive investment in recommendation systems
- 48M parameters trained on billions of examples
- Continuous experimentation and improvement
- Balance engagement with user experience
- Hybrid fanout strategy essential
- Different approaches for different user types
- Real-time updates vs. batch processing tradeoffs
Scale Statistics
- 400+ million monthly active users
- 500+ million tweets processed daily
- 1.5 seconds to generate personalized timeline
- 48 million parameters in ranking model
- 500 million → 1,500 candidates filtered in Stage 2
- Multi-region active-active architecture