What is Cache Eviction?
Cache eviction is the process of removing entries from cache when it reaches capacity. The eviction policy determines which items to remove to make room for new data.The cache eviction strategy you choose can significantly impact your system’s performance, memory usage, and hit rates.
Why Cache Eviction Matters
Caching can provide a significant performance boost by storing data in memory for faster access. However:- Cache memory is limited: Can’t store everything
- Memory is expensive: Must use it efficiently
- Data changes: Need to remove stale entries
- Access patterns vary: Different strategies suit different workloads
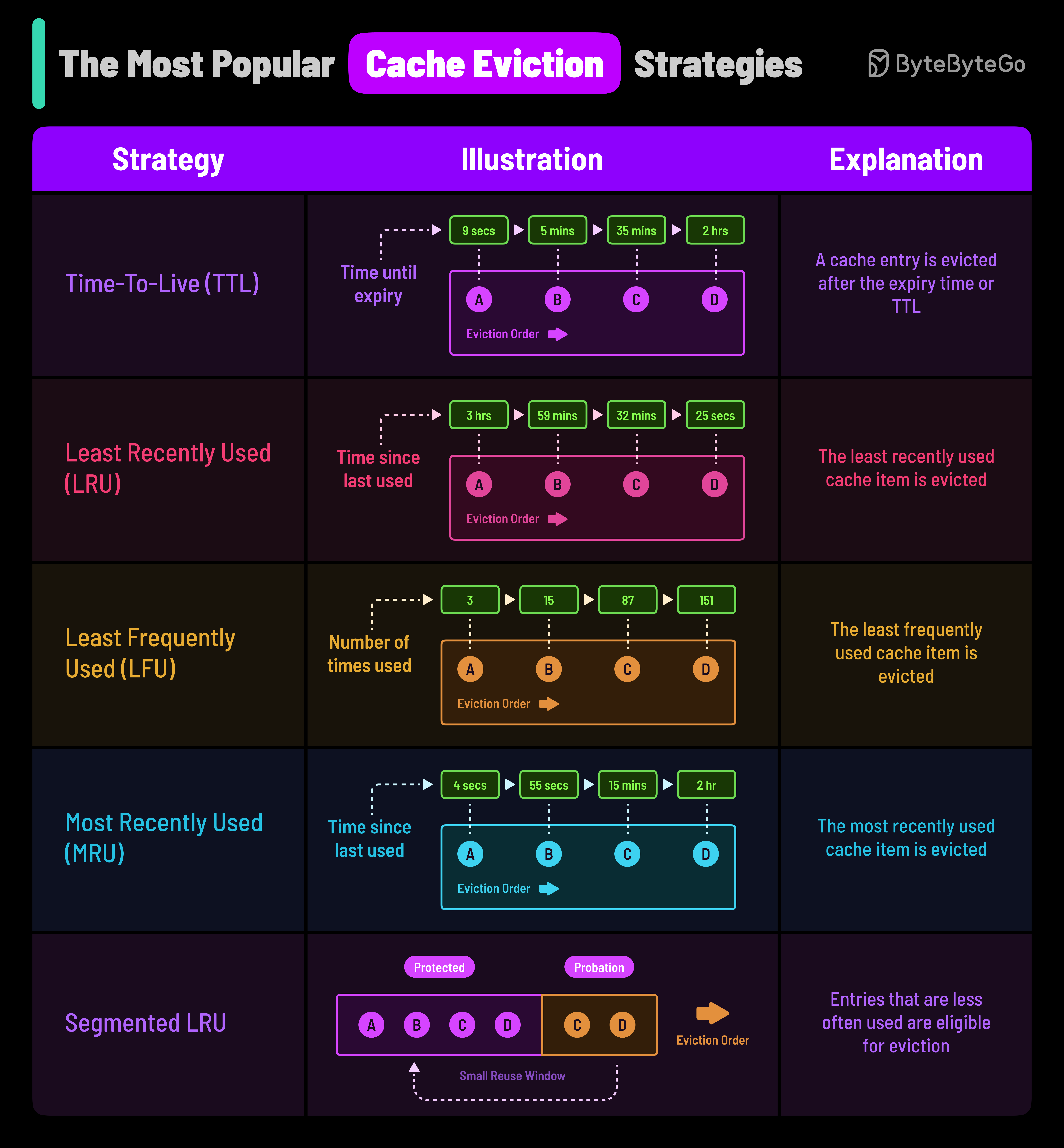
Popular Eviction Strategies
LRU (Least Recently Used)
How LRU Works
How LRU Works
Evicts the least recently accessed items first. Based on the principle that recently accessed items are more likely to be accessed again soon (temporal locality).Algorithm:
- Track access time for each cache entry
- When cache is full, remove entry with oldest access time
- Update access time on every read/write
Pros
- Good for temporal locality
- Simple to understand
- Effective for most workloads
- O(1) operations with proper data structure
Cons
- Doesn’t account for frequency
- Can evict frequently used old items
- Overhead of tracking access order
- Vulnerable to scanning
LFU (Least Frequently Used)
How LFU Works
How LFU Works
Evicts items with the lowest access frequency. Keeps track of how many times each entry is accessed.Algorithm:
- Maintain access count for each cache entry
- When cache is full, remove entry with lowest count
- Increment count on every access
Pros
- Keeps popular items
- Good for skewed access patterns
- Resistant to one-time scans
- Adapts to usage patterns
Cons
- Complex implementation
- Old popular items stick around
- Slow to adapt to changes
- Higher memory overhead
FIFO (First In First Out)
How FIFO Works
How FIFO Works
Evicts the oldest items first, regardless of access patterns. Works like a queue.Algorithm:
- Track insertion order
- When cache is full, remove oldest entry
- No consideration of access patterns
Pros
- Simplest to implement
- Predictable behavior
- Low overhead
- Fast operations
Cons
- Ignores access patterns
- Can evict hot data
- Poor cache hit rates
- Not adaptive
TTL (Time-to-Live)
How TTL Works
How TTL Works
Items are evicted after a predetermined time period, regardless of access patterns.Algorithm:
- Set expiration timestamp on insertion
- Check expiration before returning cached data
- Periodically scan and remove expired entries
Pros
- Guaranteed freshness
- Simple to implement
- Automatic cleanup
- Good for time-sensitive data
Cons
- Can evict hot data prematurely
- Requires cleanup mechanism
- Not adaptive to usage
- May waste space before expiry
MRU (Most Recently Used)
How MRU Works
How MRU Works
Evicts the most recently accessed items first. Counterintuitive but useful in specific scenarios.Algorithm:
- Track access time for each entry
- When cache is full, remove most recently accessed item
- Opposite of LRU
Pros
- Good for sequential scans
- Useful for specific patterns
- Simple implementation
Cons
- Counterintuitive
- Limited use cases
- Poor for general caching
SLRU (Segmented LRU)
How SLRU Works
How SLRU Works
Divides cache into probationary and protected segments, applying LRU separately to each.Algorithm:
- New items go to probationary segment
- On second access, promote to protected segment
- When protected is full, demote to probationary
- Apply LRU within each segment
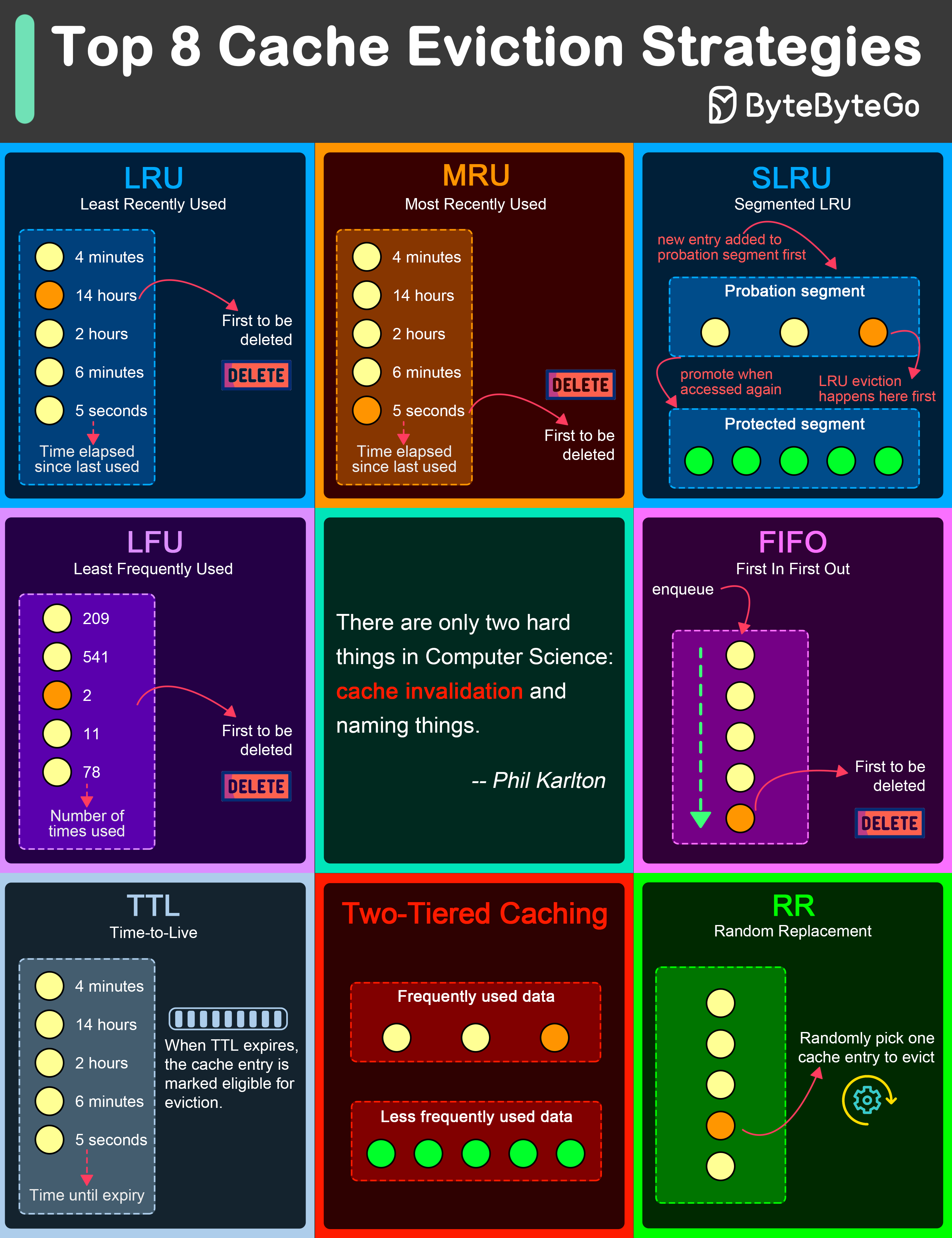
Pros
- Protects frequently accessed items
- Better than simple LRU
- Adapts to access patterns
- Resists scanning
Cons
- More complex
- Higher memory overhead
- Tuning required
RR (Random Replacement)
How RR Works
How RR Works
Randomly selects and evicts a cache item when space is needed.
Pros
- Extremely simple
- Fast
- No tracking overhead
- Unpredictable (can be good)
Cons
- Can evict hot data
- No guarantees
- Poor performance
- Not recommended for production
Strategy Comparison
- Performance
- Use Cases
- Workload Match
| Strategy | Hit Rate | Memory Overhead | Complexity | Best For |
|---|---|---|---|---|
| LRU | High | Medium | Medium | General purpose |
| LFU | Very High | High | High | Skewed access |
| FIFO | Low | Low | Low | Simple caching |
| TTL | Variable | Low | Low | Time-sensitive |
| MRU | Low | Low | Medium | Sequential scans |
| SLRU | Very High | High | High | Large systems |
| RR | Very Low | Very Low | Very Low | Testing |
Two-Tiered Caching
Combining multiple cache layers can provide better overall performance.
Best Practices
Choose based on access patterns
- Random access: LRU or LFU
- Time-sensitive: TTL
- Sequential: MRU
- Mixed: SLRU or combination
Common Pitfalls
Cache Stampede
Cache Stampede
When a popular item expires, multiple requests hit the database simultaneously.Solution:
Cache Pollution
Cache Pollution
One-time scans filling cache with rarely accessed data.Solution:
- Use SLRU instead of LRU
- Implement bloom filters
- Separate cache for scan operations
Inconsistent TTLs
Inconsistent TTLs
Different TTLs for related data causing inconsistency.Solution:
Next Steps
Redis Caching
Learn how to implement these strategies with Redis
Caching Strategies
Explore read/write caching patterns
CDN Caching
Understand edge caching and distribution