Introduction
The CAP theorem is one of the most famous concepts in computer science, but also one of the most misunderstood. Proposed by Eric Brewer in 2000 and formally proven by Seth Gilbert and Nancy Lynch in 2002, it fundamentally shapes how we design distributed systems.The CAP theorem is often referenced in database selection, but understanding its nuances is critical for making the right architectural decisions.
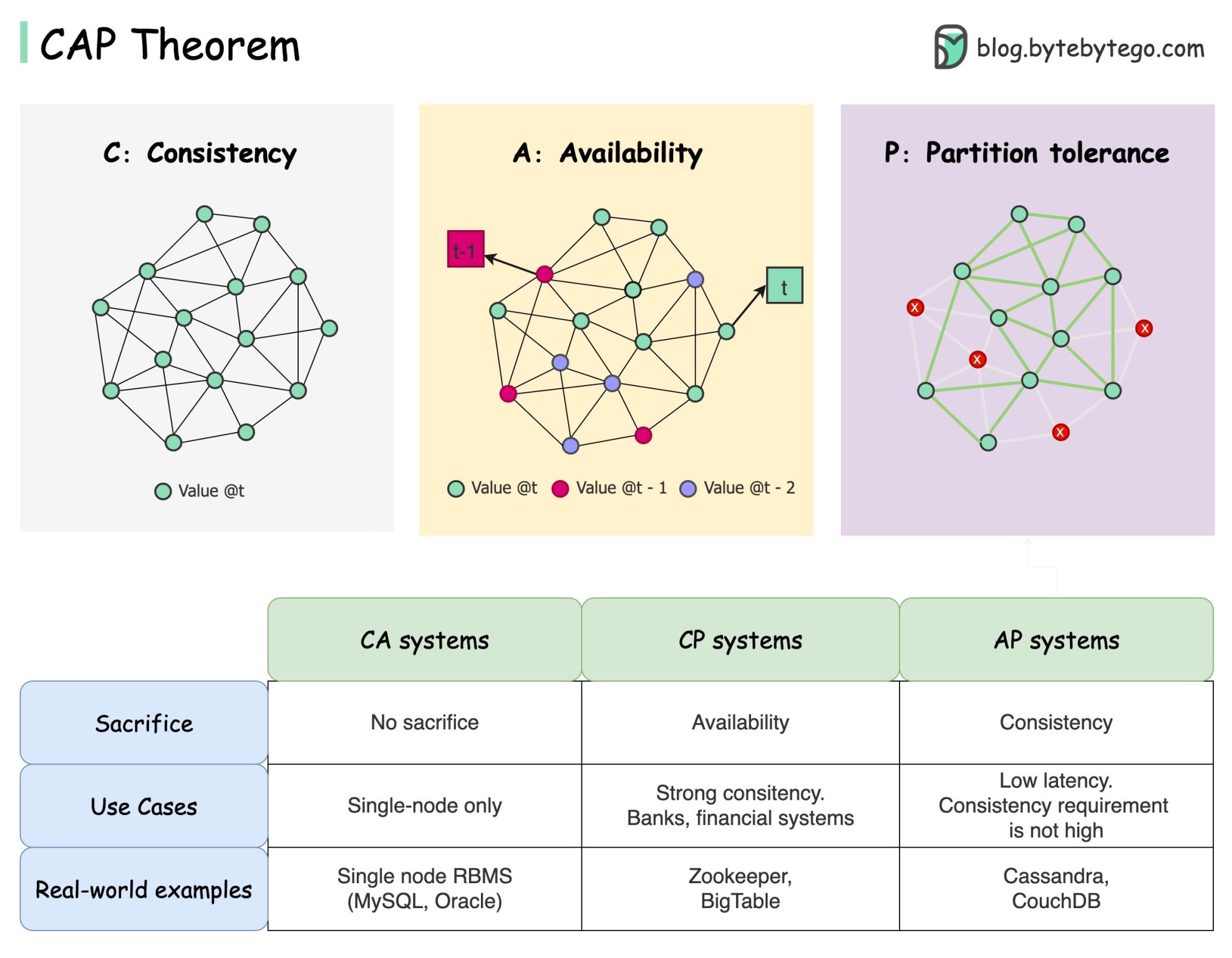
What is the CAP Theorem?
The CAP theorem states that a distributed system can’t provide more than two of these three guarantees simultaneously:Consistency
All clients see the same data at the same time, no matter which node they connect to
Availability
Any client requesting data gets a response, even if some nodes are down
Partition Tolerance
The system continues to operate despite network partitions (communication breakdowns)
The Three Guarantees Explained
Consistency (C)
Definition: All clients see the same data at the same time, no matter which node they connect to. Consistency in CAP means that a read operation will return the most recent write. If you write a value to node A, then immediately read from node B, you’ll see that newly written value.This is different from “Consistency” in ACID, which refers to maintaining database invariants and constraints.
Availability (A)
Definition: Any client which requests data gets a response, even if some of the nodes are down. Availability means every request receives a non-error response, regardless of the state of any individual nodes. The system remains operational and responsive.Partition Tolerance (P)
Definition: The system continues to operate despite network partitions. A partition is a communication break between nodes—they can’t talk to each other. Partition tolerance means the system continues functioning even when nodes can’t communicate.The Trade-offs: Pick Two?
The traditional “pick two out of three” framing can be misleading. Let’s examine what each combination means:CP: Consistency + Partition Tolerance
Trade-off: Sacrifice availability during network partitions. When a partition occurs, the system must reject requests to maintain consistency.- Strong consistency guarantees
- May return errors during partitions
- Prioritizes correctness over availability
- HBase: Blocks operations until partition heals
- MongoDB (with majority write concern): May refuse writes
- Redis (with strong consistency configuration)
- Etcd, ZooKeeper: Prefer consistency for coordination
- Financial systems where correctness is paramount
- Inventory management systems
- Coordination services (leader election, configuration)
- Systems where stale data causes serious problems
AP: Availability + Partition Tolerance
Trade-off: Sacrifice consistency during network partitions. The system remains available and responsive but may return stale or divergent data.- Always responsive
- May return stale data
- Eventually becomes consistent
- Cassandra: Always available, eventually consistent
- DynamoDB: Configurable but can prioritize availability
- Riak: Designed for high availability
- CouchDB: Multi-master with conflict resolution
- Social media feeds (stale tweets are acceptable)
- Product catalogs (slight staleness is tolerable)
- Chat applications (message delivery over ordering)
- Shopping carts (temporary inconsistency is acceptable)
CA: Consistency + Availability
Trade-off: Not partition tolerant. This combination only works in non-distributed systems or when you can guarantee no network partitions (which is impossible in reality). Examples:- Single-node databases: PostgreSQL, MySQL (on one server)
- Traditional RDBMS without replication
Common Misconceptions
Misconception 1: “Pick Two” is Complete
The CAP theorem “prohibits only a tiny part of the design space: perfect availability and consistency in the presence of partitions, which are rare.” — Eric Brewer, “CAP Twelve Years Later: How the ‘Rules’ Have Changed”Misconception 2: The Choice is Binary
Modern databases offer tunable consistency:Misconception 3: CAP is About 100%
The theorem is about perfect availability and perfect consistency. In practice, systems make trade-offs:- 99.9% availability (not 100%)
- Eventually consistent (not always consistent)
- Tunable consistency levels
Misconception 4: CAP is Sufficient for Database Selection
When choosing Cassandra for chat messages, consider:- Write-heavy workload (Cassandra excels here)
- Time-series data model fits well
- Horizontal scalability needs
- Operational maturity and team skills
- Not just “it’s AP”
PACELC Theorem: A More Nuanced View
The PACELC theorem extends CAP to be more realistic: PACELC stands for:- If Partition (P): Choose between Availability (A) and Consistency (C)
- Else (E): Choose between Latency (L) and Consistency (C)
PACELC recognizes that even when there’s no partition, you must trade off latency against consistency.
The Latency vs Consistency Trade-off
When the network is healthy (no partition): Lower latency → Weaker consistency:- PA/EL: Cassandra, Riak (Available during partition, Low latency during normal operation)
- PC/EC: HBase, MongoDB (Consistent during partition, Consistent during normal operation)
- PA/EC: DynamoDB (Available during partition, Consistent during normal operation)
Real-World Systems
Most modern databases allow you to tune the trade-off:DynamoDB
Cassandra
MongoDB
Design Implications
Detecting Partitions
Systems must detect when partitions occur:Conflict Resolution (AP Systems)
When choosing availability over consistency, systems need conflict resolution: Last Write Wins (LWW):Practical Guidelines
When to Choose CP (Consistency + Partition Tolerance)
Financial transactions where accuracy is critical
Inventory systems (can’t oversell products)
Coordination services (leader election, locking)
Systems where stale data causes real problems
- Possible downtime during partitions
- Higher latency for writes
- Lower availability
When to Choose AP (Availability + Partition Tolerance)
Social media feeds and content
Recommendation systems
Caching layers
Analytics and monitoring
Shopping carts (temporary inconsistency acceptable)
- Eventual consistency
- Possible stale data
- Need for conflict resolution
- More complex application logic
Is the CAP Theorem Really Useful?
Yes, but with caveats:It Opens Discussion
It Opens Discussion
CAP opens our minds to trade-off discussions in distributed systems. It forces us to think about failure modes.
It's Part of the Story
It's Part of the Story
CAP is only part of the story. We need to dig deeper when picking the right database, considering:
- Latency requirements
- Query patterns
- Operational complexity
- Team expertise
- Performance characteristics
It Highlights Fundamental Limits
It Highlights Fundamental Limits
CAP reminds us that there are fundamental trade-offs in distributed systems. There’s no perfect solution.
Use CAP as a starting point for discussion, not as the sole criterion for database selection.
Conclusion
The CAP theorem teaches us:- Partition tolerance is mandatory in distributed systems
- Trade-offs are inevitable between consistency and availability during partitions
- The “pick two” framing is oversimplified—real systems offer tunable trade-offs
- PACELC provides a more complete picture including latency considerations
- Database selection requires more than CAP—consider the full context
Next Steps
ACID Properties
Understand transaction guarantees in databases
Database Replication
Learn how replication affects consistency
Database Sharding
Explore horizontal scaling strategies
Distributed Systems
Learn about distributed system patterns