Introduction
Distributed systems are complex by nature, requiring careful design to handle challenges like network partitions, data consistency, and fault tolerance. This guide covers the most important patterns used in production distributed systems.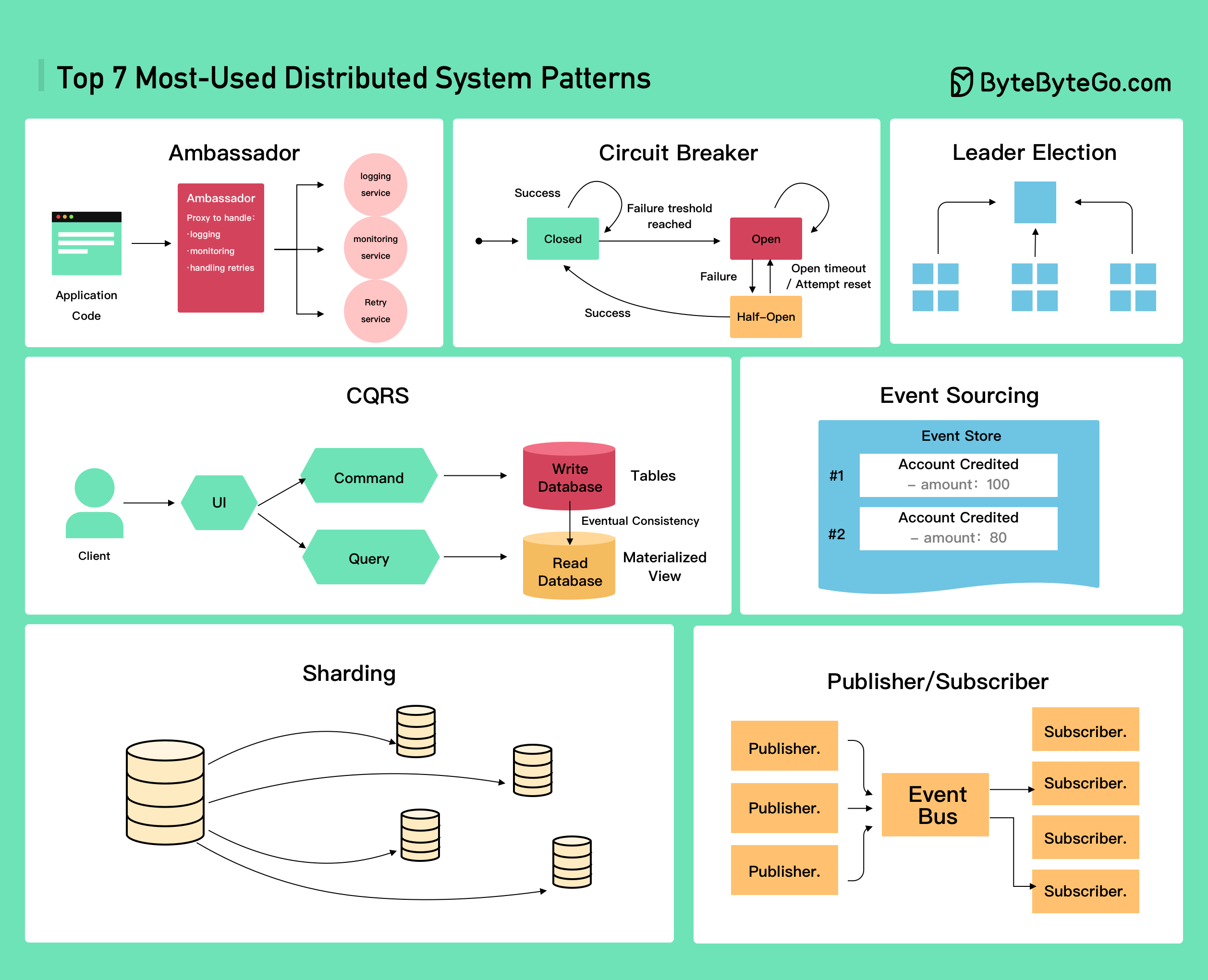
Top 7 Distributed System Patterns
The most commonly used patterns in distributed system design are:- Ambassador
- Circuit Breaker
- CQRS (Command Query Responsibility Segregation)
- Event Sourcing
- Leader Election
- Publisher/Subscriber
- Sharding
1. Ambassador Pattern
The Ambassador pattern places a helper service (ambassador) alongside your application to handle common connectivity tasks. Use Cases:- Offload common client connectivity tasks
- Handle retries and timeouts
- Implement monitoring and logging
- Provide connection pooling
- Language-agnostic
- Simplified application code
- Centralized connectivity logic
- Easier to update connection logic
2. Circuit Breaker Pattern
The Circuit Breaker pattern prevents an application from repeatedly trying to execute an operation that’s likely to fail. States:
Configuration Parameters:
- Failure Threshold: Number of failures before opening circuit
- Timeout Duration: How long circuit stays open
- Success Threshold: Successful requests needed to close circuit
- Prevents cascading failures
- Fails fast
- Allows system to recover
- Improves user experience
3. CQRS (Command Query Responsibility Segregation)
 CQRS separates read and write operations into different models.
Architecture:
CQRS separates read and write operations into different models.
Architecture:
- Command Side (Write)
- Query Side (Read)
- Handles all write operations
- Optimized for data modification
- Validates business rules
- Emits events on changes
- Can use normalized data model
- Different read/write performance requirements
- Complex business logic on writes
- Need for multiple view models
- High read/write ratio imbalance
- Independent scaling of reads and writes
- Optimized data models for each operation
- Better performance
- Flexibility in data representation
- Increased complexity
- Eventual consistency
- More infrastructure
- Synchronization overhead
4. Event Sourcing Pattern
Instead of storing just the current state, Event Sourcing stores the sequence of events that led to the current state. Key Concepts:Event Store
Append-only log of all events. Single source of truth for system state.
Event
Immutable fact that something happened. Contains timestamp and data.
Projection
Current state derived by replaying events. Multiple projections possible.
Snapshot
Periodic checkpoint of state to improve performance. Optional optimization.
- Complete audit trail
- Time travel queries
- Easy to debug
- Replay events for new projections
- Natural fit for event-driven architectures
- Storage requirements grow over time
- Eventual consistency
- Learning curve
- Schema evolution
- Financial systems (transactions)
- Audit requirements
- Collaborative systems
- Time-based analytics
5. Leader Election Pattern
Leader Election ensures that only one node in a distributed system performs a specific task at a time. Common Algorithms:Raft
Raft
Consensus algorithm designed for understandability.Features:
- Strong consistency
- Leader-based
- Log replication
- Used in etcd, Consul
Paxos
Paxos
Classic consensus algorithm.Features:
- Proven correctness
- Complex to implement
- Multiple variants (Multi-Paxos, Fast Paxos)
- Academic foundation
Bully Algorithm
Bully Algorithm
Simple election algorithm based on process IDs.Features:
- Highest ID becomes leader
- Easy to understand
- Less efficient than Raft/Paxos
ZooKeeper
ZooKeeper
Distributed coordination service.Features:
- Ephemeral nodes for leader election
- Watches for change notifications
- Sequential znodes
- Widely used in production
- Database primary election
- Job scheduling coordination
- Configuration management
- Distributed locking
6. Publisher/Subscriber Pattern
Pub/Sub pattern enables asynchronous communication between services without direct coupling. Architecture:- Loose Coupling: Publishers don’t know about subscribers
- Scalability: Add subscribers without affecting publishers
- Asynchronous: Fire and forget communication
- Broadcasting: One message to many subscribers
- Kafka: High-throughput, distributed event streaming
- RabbitMQ: Traditional message broker
- AWS SNS/SQS: Managed pub/sub service
- Google Pub/Sub: Cloud-native messaging
- Redis Pub/Sub: Lightweight, in-memory
- Fan-out
- Work Queue
- Topic-based
One message to multiple subscribersUse: Event broadcasting, notifications
7. Sharding Pattern
Sharding distributes data across multiple databases to improve scalability and performance. Covered in detail in the Scalability GuideConsistent Hashing
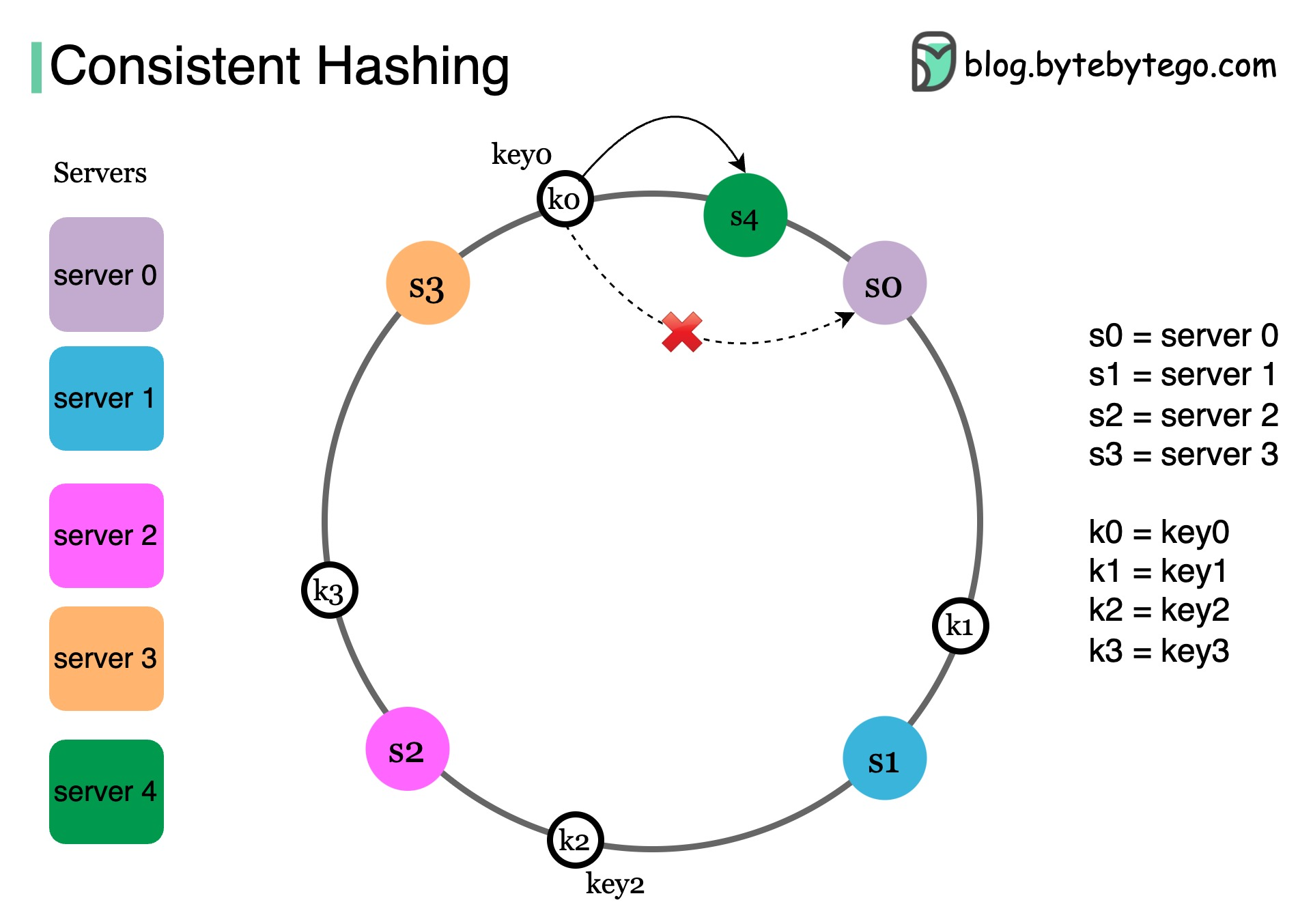 What do Amazon DynamoDB, Apache Cassandra, Discord, and Akamai CDN have in common? They all use consistent hashing.
What do Amazon DynamoDB, Apache Cassandra, Discord, and Akamai CDN have in common? They all use consistent hashing.
The Problem with Simple Hashing
In a large-scale distributed system, data doesn’t fit on a single server. Using simple hashing:Consistent Hashing Solution
How it works:
Benefits:
- Minimal key remapping when servers change
- Only K/N keys need to move (K = total keys, N = servers)
- Scalable and efficient
- Amazon DynamoDB: Minimize data movement during rebalancing
- Apache Cassandra: Distribute data across nodes
- CDNs (Akamai): Distribute web content evenly among edge servers
- Load Balancers: Distribute persistent connections across backend servers
Failure Detection in Distributed Systems
 Heartbeat mechanisms are crucial for monitoring the health and status of components in distributed systems.
Heartbeat mechanisms are crucial for monitoring the health and status of components in distributed systems.
Heartbeat Mechanisms
Push-Based Heartbeat
Push-Based Heartbeat
Nodes periodically send heartbeat signals to a monitor.Pros: Simple to implementCons: Network congestion can cause false positives
Pull-Based Heartbeat
Pull-Based Heartbeat
Central monitor periodically queries nodes for status.Pros: Reduces network traffic from nodesCons: Increased latency in failure detection
Heartbeat with Health Check
Heartbeat with Health Check
Includes diagnostic information (CPU, memory, metrics).Pros: More detailed information, nuanced decision-makingCons: Larger network overhead, increased complexity
Heartbeat with Timestamps
Heartbeat with Timestamps
Includes timestamps to detect network delays.Pros: Distinguishes between node failure and network issuesCons: Requires clock synchronization
Heartbeat with Acknowledgement
Heartbeat with Acknowledgement
Receiver must acknowledge receipt of heartbeat.Pros: Verifies network path is functionalCons: Double the network traffic
Heartbeat with Quorum
Heartbeat with Quorum
Uses majority voting for consensus protocols (Paxos, Raft).Pros: Ensures sufficient nodes for decision-makingCons: Complex implementation, quorum management overhead
CAP Theorem
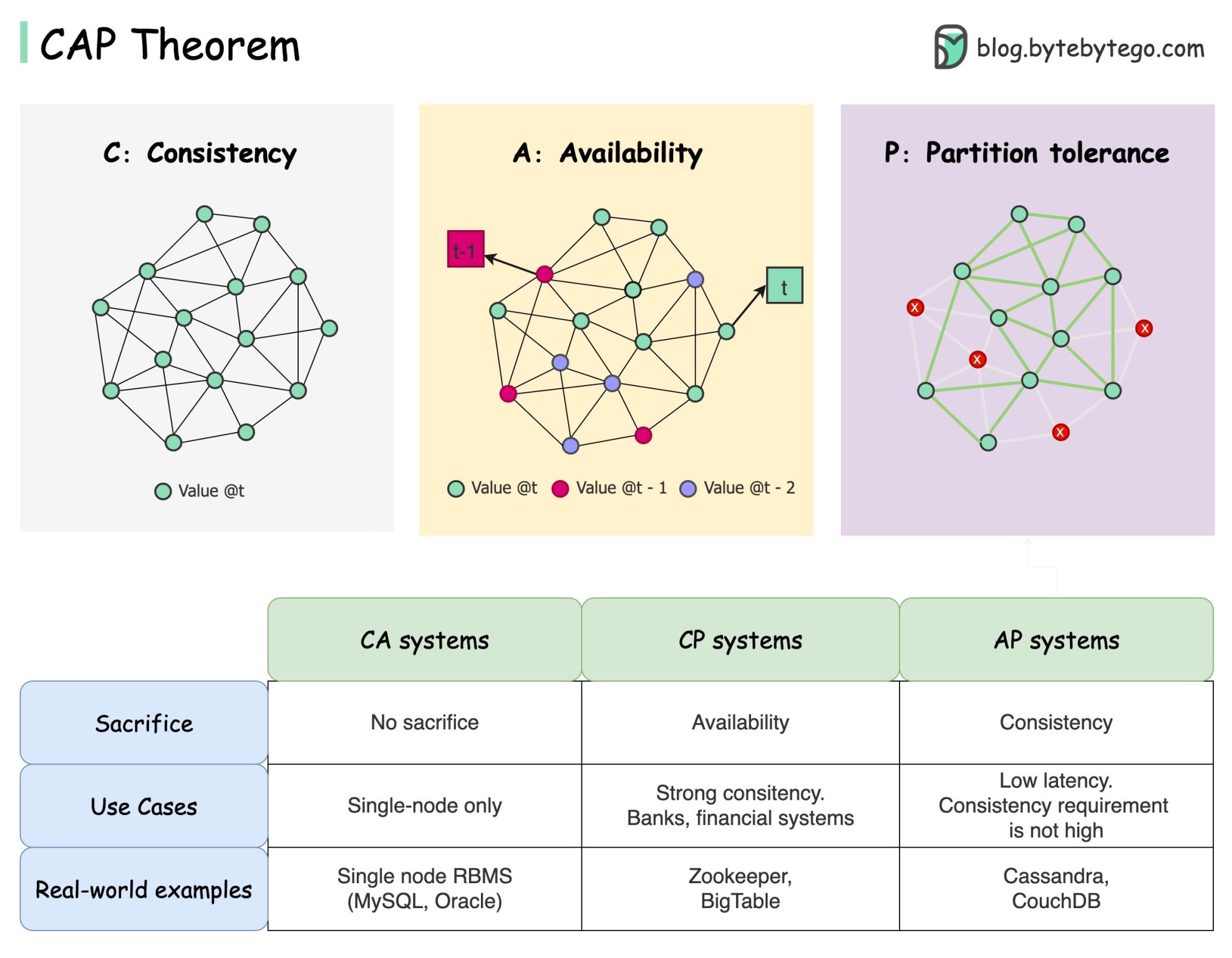 The CAP theorem states that a distributed system can’t provide more than two of these three guarantees simultaneously:
The CAP theorem states that a distributed system can’t provide more than two of these three guarantees simultaneously:
The Three Guarantees
Consistency
All clients see the same data at the same time no matter which node they connect to.
Availability
Any client requesting data gets a response even if some nodes are down.
Partition Tolerance
The system continues to operate despite network partitions.
Understanding the Trade-offs
Database Examples:-
CP Systems (Consistency + Partition Tolerance)
- MongoDB, HBase, Redis
- Prefer consistency over availability
- May return errors during partitions
-
AP Systems (Availability + Partition Tolerance)
- Cassandra, DynamoDB, CouchDB
- Prefer availability over consistency
- May return stale data during partitions
-
CA Systems (Consistency + Availability)
- Traditional RDBMS (PostgreSQL, MySQL)
- In single-node or same datacenter
- Cannot tolerate network partitions
CAP opens our minds to trade-off discussions, but it’s only part of the story. Consider PACELC theorem for a more complete picture: in case of Partition, choose Availability or Consistency; Else, choose Latency or Consistency.
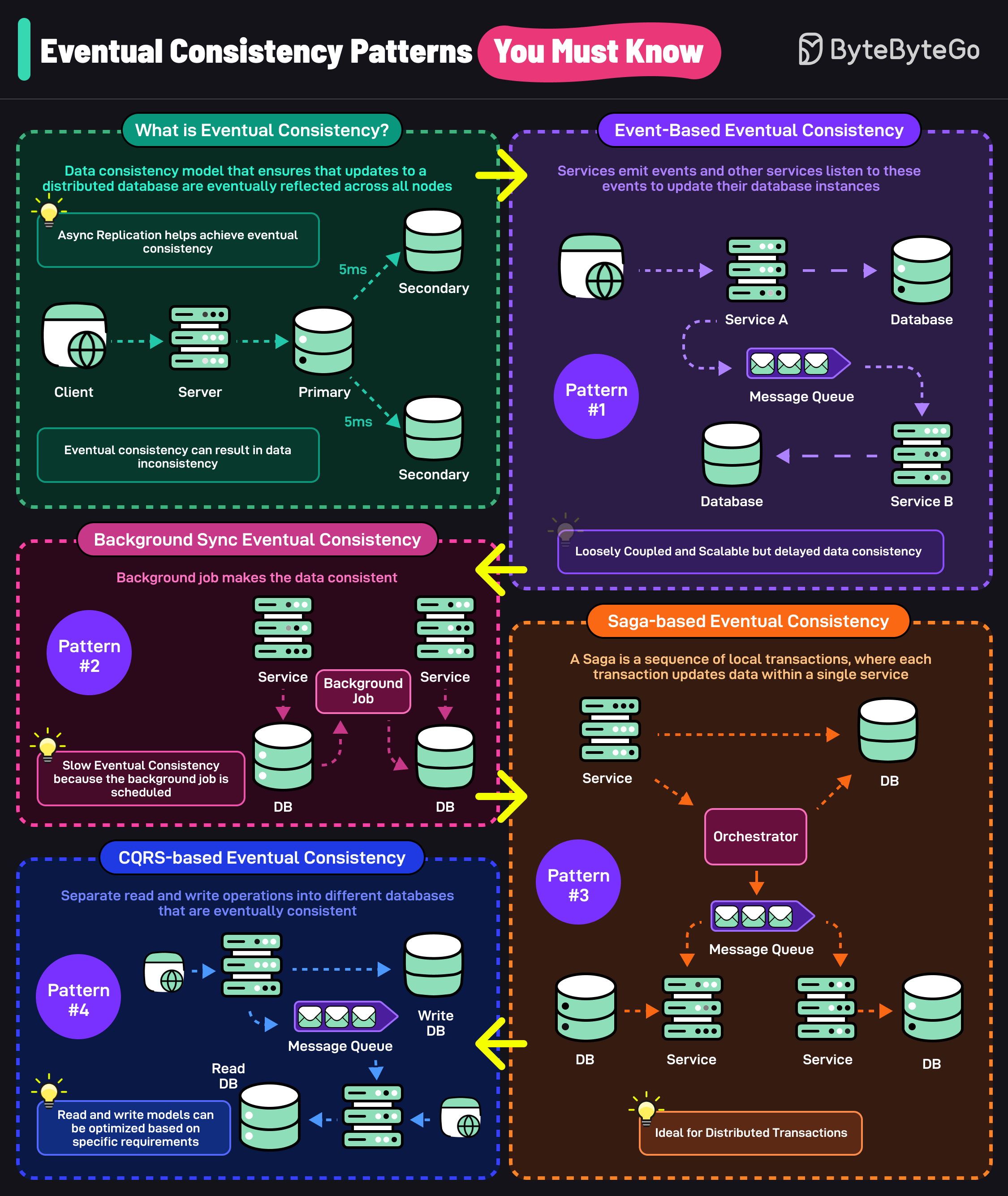
Eventual Consistency Patterns
Eventual consistency ensures that updates to a distributed database are eventually reflected across all nodes.Event-based Eventual Consistency
Services emit events and other services listen to update their database instances. Characteristics:- Loosely coupled services
- Asynchronous communication
- Delays in data consistency
- Scalable architecture
Background Sync Eventual Consistency
A background job makes data consistent across databases on a schedule. Characteristics:- Slower eventual consistency
- Lower system load
- Predictable sync patterns
- Simpler implementation
Saga-based Eventual Consistency
Sequence of local transactions where each transaction updates data within a single service. Patterns:- Choreography: Each service publishes events
- Orchestration: Central coordinator manages saga
CQRS-based Eventual Consistency
Separate read and write operations into different databases that are eventually consistent. Benefits:- Optimized read and write models
- Independent scaling
- Flexibility in data representation
Best Practices
Design for Failure
Assume components will fail and build redundancy into your system.
Idempotency
Make operations idempotent so they can be safely retried.
Loose Coupling
Use message queues and events to decouple services.
Monitoring
Implement comprehensive monitoring and alerting.
-
Use timeouts appropriately
- Set reasonable timeout values
- Implement retry with backoff
- Consider timeout at each layer
-
Implement circuit breakers
- Protect against cascading failures
- Allow systems to recover
- Provide fallback mechanisms
-
Design for observability
- Distributed tracing
- Structured logging
- Metrics and monitoring
- Correlation IDs
-
Test for failure scenarios
- Chaos engineering
- Network partition testing
- Load testing
- Disaster recovery drills
Cloud-Native Considerations
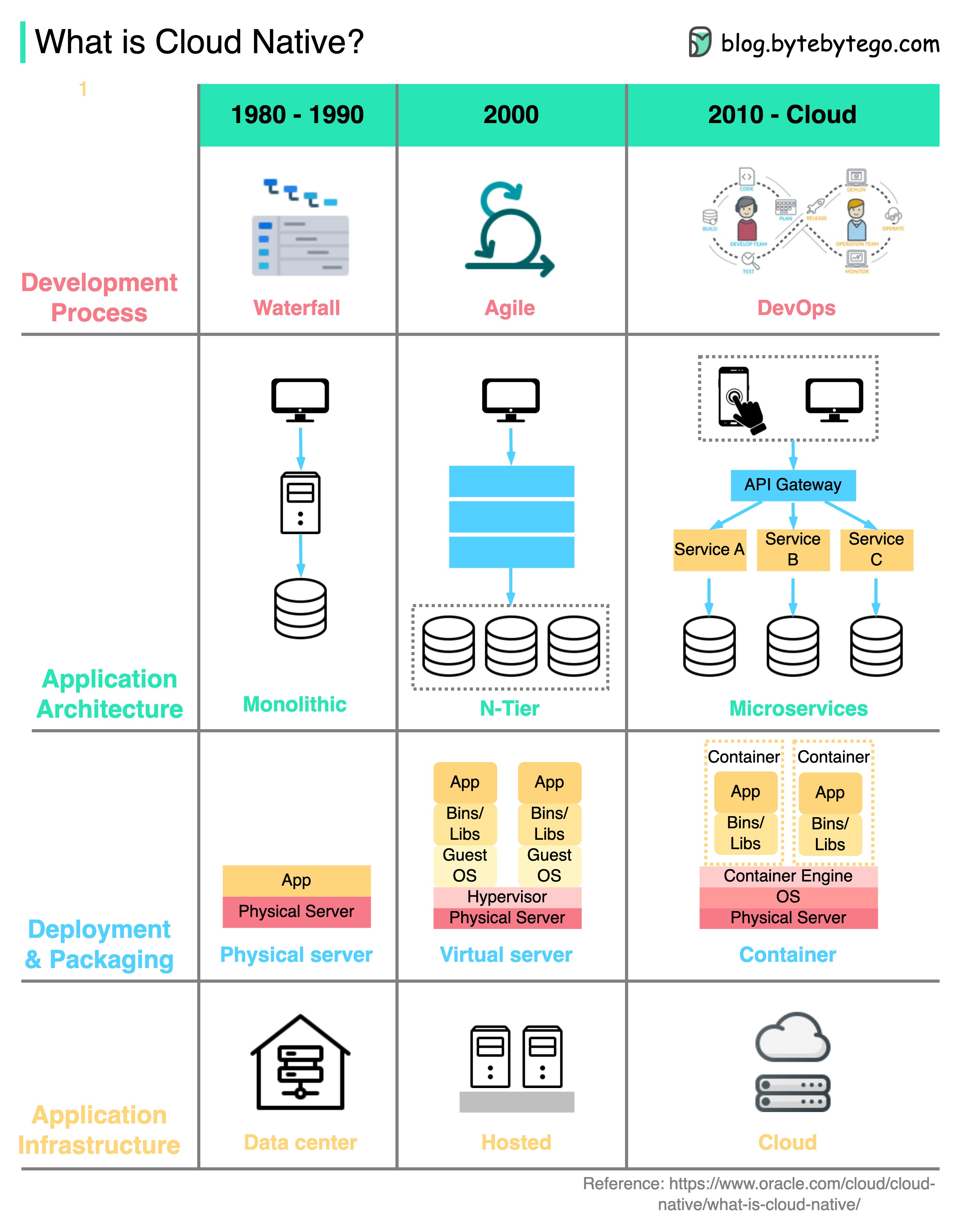 Cloud native technologies enable organizations to build and run scalable applications in public, private, and hybrid clouds.
Four Aspects of Cloud Native:
Cloud native technologies enable organizations to build and run scalable applications in public, private, and hybrid clouds.
Four Aspects of Cloud Native:
- Development Process: Waterfall → Agile → DevOps
- Application Architecture: Monolithic → Microservices
- Deployment & Packaging: Physical → Virtual → Containers
- Infrastructure: Self-hosted → Cloud
Related Topics
AWS Services
Explore AWS services for distributed systems
Scalability
Learn strategies for scaling systems
Resilience
Build resilient and fault-tolerant systems