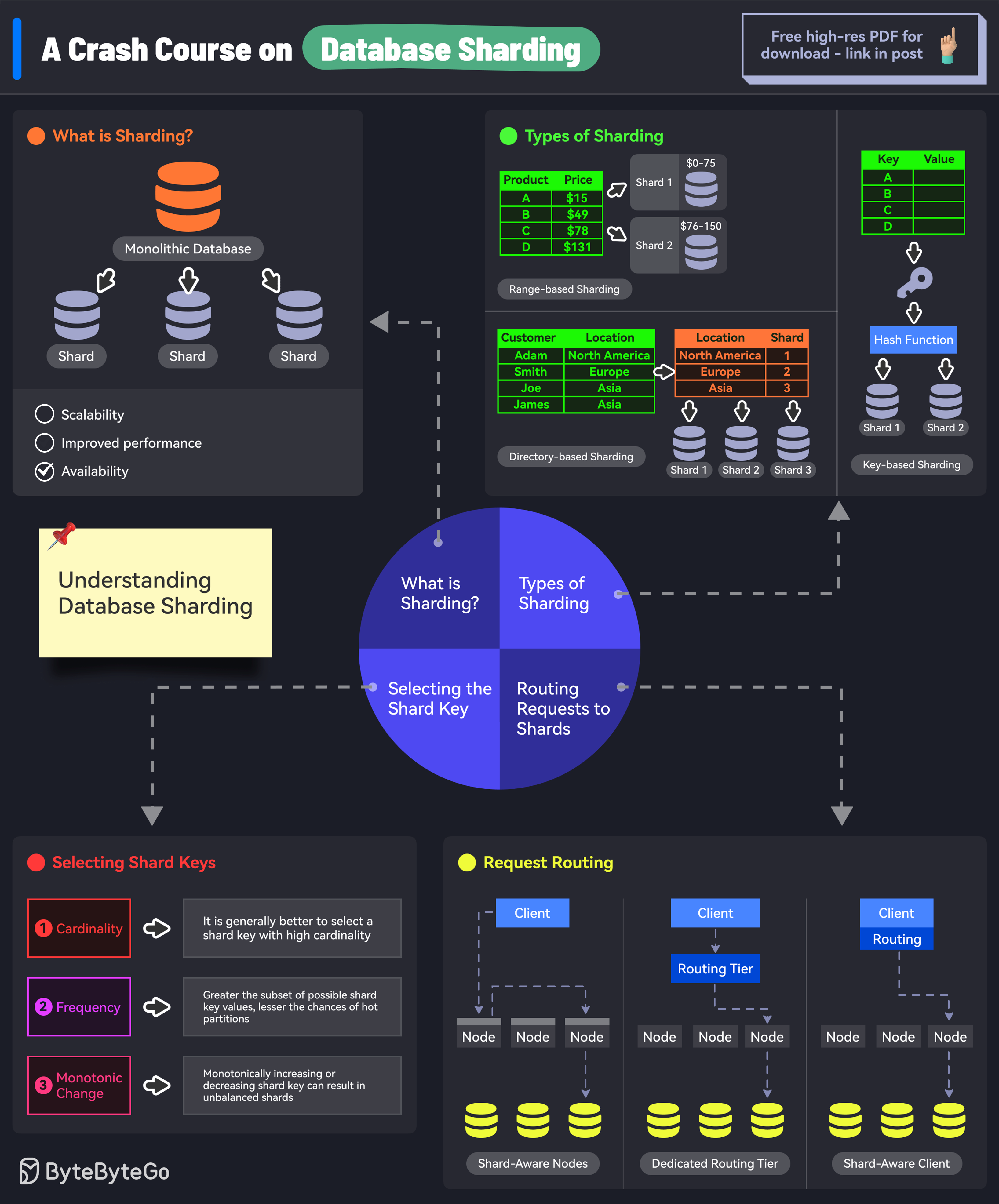
What is Database Sharding?
Database sharding is a type of database partitioning that separates very large databases into smaller, faster, more easily managed parts called data shards. The word “shard” means a small piece of something bigger.Sharding is also known as horizontal partitioning. Each shard contains a portion of the data, and all shards together contain all of the data.
Why Implement Sharding?
Sharding solves critical scalability problems that arise as your application grows:Data Volume
Too much data on one machine: A single database server can only handle so much data before performance degrades.
Request Load
Too many requests: A single database server has limited capacity to handle concurrent requests.
Query Performance
High Latency: As data grows, query latency increases, impacting user experience.
- Distribute load across multiple servers
- Improve query response times
- Scale horizontally by adding more machines
- Isolate failures to individual shards
How Sharding Works
Sharding involves splitting a database into multiple, independent parts (shards) and distributing them across different servers or machines. Each shard contains a subset of the data, and all shards collectively hold the entire dataset.Core Concepts
Sharding Key
A sharding key (also called partition key) is a column in the database table that determines how the data is distributed across the shards. Characteristics of a good sharding key:- High cardinality (many unique values)
- Evenly distributed data
- Aligned with common query patterns
- Relatively stable (doesn’t change frequently)
- User ID for user-centric applications
- Geographic region for location-based services
- Timestamp for time-series data
- Tenant ID for multi-tenant systems
Sharding Algorithms
The sharding algorithm is the logic that determines which shard a particular row of data should be stored in. The algorithm uses the sharding key to make this determination.Sharding Algorithms Explained
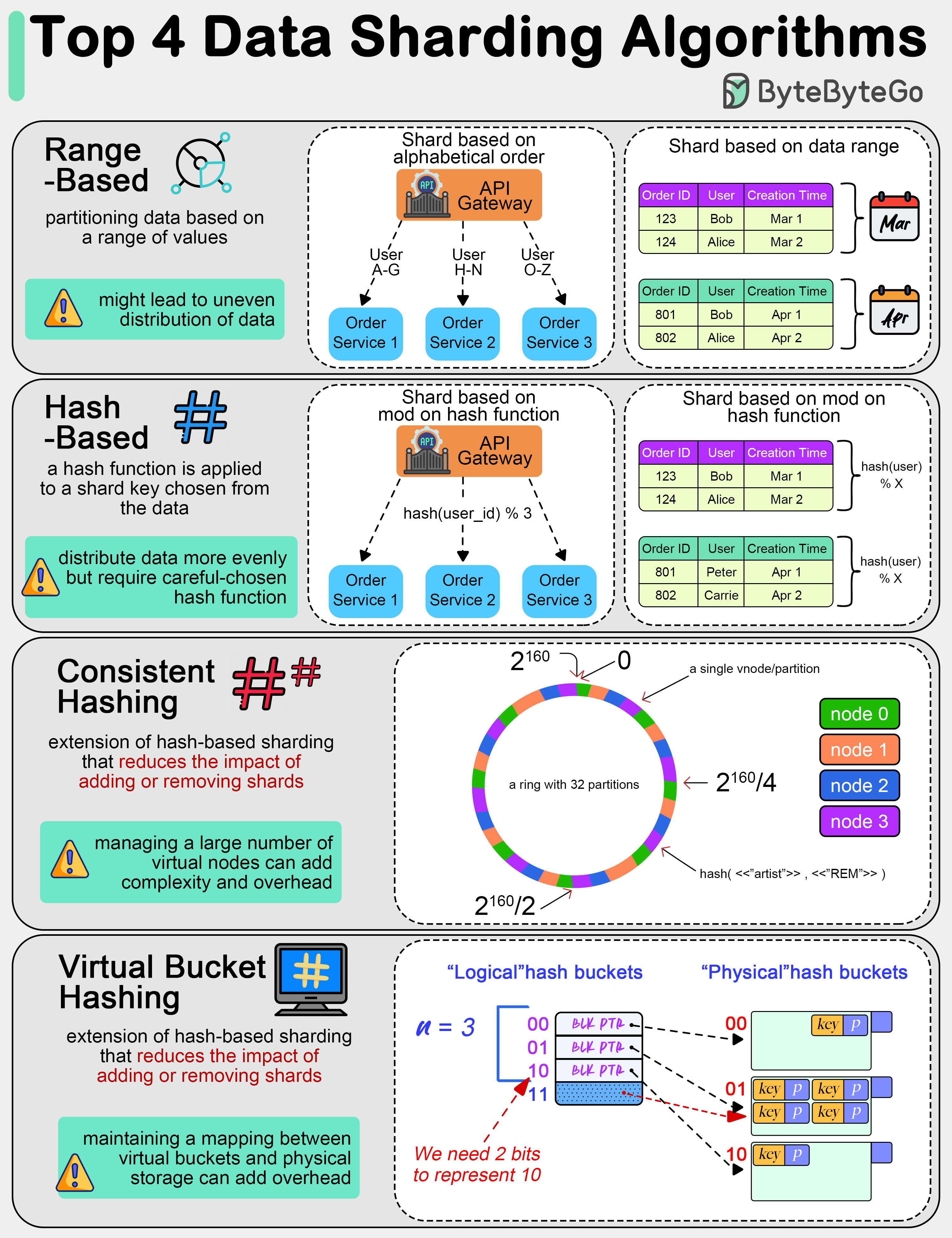
1. Range-Based Sharding
Data is divided into ranges based on the sharding key value. How it works:Pros and Cons
Pros and Cons
Advantages:
- Simple to implement and understand
- Range queries are efficient (e.g., “users 100-200”)
- Easy to add new shards for new ranges
- Risk of uneven distribution (hotspots)
- Newer data often gets more traffic
- Sequential IDs can create bottlenecks
2. Hash-Based Sharding
A hash function is applied to the sharding key to determine the shard. How it works:Pros and Cons
Pros and Cons
Advantages:
- Even distribution of data across shards
- Eliminates hotspot issues
- Simple and predictable
- Range queries are inefficient
- Adding/removing shards requires redistribution
- Must choose a good hash function to avoid collisions
3. Consistent Hashing
An extension of hash-based sharding that reduces the impact of adding or removing shards. How it works:- Both data and nodes are hashed onto a circular ring (0 to 2^32-1)
- Data is assigned to the first node clockwise from its position
- Adding/removing nodes only affects adjacent data
Consistent hashing minimizes data movement when the cluster changes. Only K/n keys need to be remapped (where K is total keys and n is number of servers).
- Minimal data redistribution when scaling
- Better fault tolerance
- Flexible cluster membership
4. Virtual Bucket Sharding
Data is mapped to virtual buckets, which are then mapped to physical shards. How it works:- Move buckets between shards without rehashing
- Rebalance load by redistributing buckets
- Scale by adding shards and moving buckets
- Flexible rebalancing without data movement
- Easy to add/remove physical servers
- Can optimize for different server capacities
Sharding Approaches
Application-Level Sharding
The application code is responsible for determining which shard to use for each query.Pros and Cons
Pros and Cons
Advantages:
- Full control over sharding logic
- No additional infrastructure
- Can optimize for specific use cases
- Complexity in application code
- Harder to maintain and change
- Every application must implement routing
Middleware Sharding
A middleware layer (proxy) sits between the application and databases, handling sharding logic.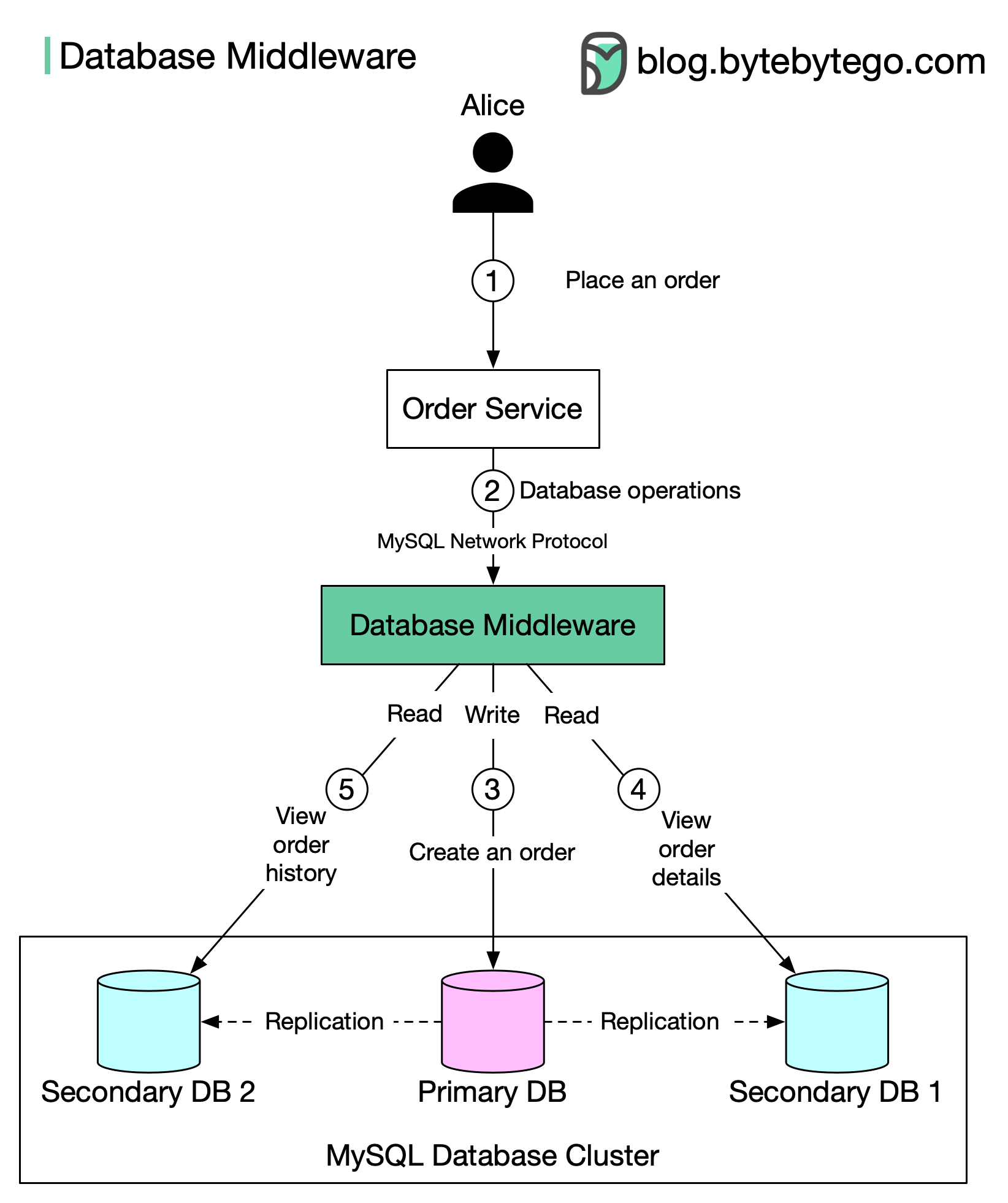
Pros and Cons
Pros and Cons
Advantages:
- Simplified application code
- Centralized routing logic
- Better compatibility (uses standard protocols)
- Easier to change sharding strategy
- Additional network hop (latency)
- Potential single point of failure
- Requires high-availability setup
- Complex middleware system to maintain
Database-Native Sharding
The database system itself provides built-in sharding capabilities. Examples:- MongoDB (automatic sharding)
- Cassandra (partition keys)
- CockroachDB (automatic distribution)
- Citus (PostgreSQL extension)
Pros and Cons
Pros and Cons
Advantages:
- Transparent to application
- Optimized by database vendor
- Automatic rebalancing
- Integrated monitoring
- Vendor lock-in
- Less control over sharding logic
- May not fit all use cases
- Learning curve for specific database
Sharding Challenges
1. Increased Complexity
Sharding adds complexity to every aspect of your system:- Application code must be shard-aware
- Deployment becomes more complex
- Monitoring requires tracking multiple databases
- Backup and recovery is more involved
2. Data Distribution
Choosing the right sharding key and algorithm is crucial:- Poor choices lead to uneven distribution
- Hotspots can bottleneck performance
- Difficult to change once implemented
3. Cross-Shard Queries
Queries spanning multiple shards are challenging: Joins across shards:- Denormalize data to avoid cross-shard joins
- Perform joins at application level
- Use distributed query engines
- Design schema to minimize cross-shard queries
4. Distributed Transactions
Transactions spanning multiple shards require:- Two-phase commit protocols
- Distributed transaction coordinators
- Handling partial failures
- Increased latency
5. Resharding
Changing the sharding scheme after implementation is complex:- Requires data migration across shards
- Can cause downtime
- Risk of data inconsistency
- Significant engineering effort
- Use consistent hashing or virtual buckets
- Over-provision shards initially
- Plan for growth in initial design
- Use database-native sharding with automatic rebalancing
Best Practices
Choose Your Sharding Key Carefully
Analyze query patterns and select a key that distributes data evenly and aligns with common queries.
Design for Sharding Early
Even if not implementing immediately, design your schema to be shard-friendly.
Minimize Cross-Shard Operations
Structure your data model to keep related data together on the same shard.
When to Shard
Consider sharding when:Database size exceeds what a single server can handle efficiently
Write throughput exceeds single server capacity
Read replicas can’t keep up with read load
You need better geographic distribution
Regulatory requirements mandate data locality
- Optimize queries and add proper indexes
- Implement caching (Redis, Memcached)
- Add read replicas for read-heavy workloads
- Vertical scaling (bigger server)
- Partition tables within the same database
Conclusion
Sharding is a powerful technique for scaling databases horizontally, but it comes with significant complexity. Success requires:- Careful selection of sharding keys
- Appropriate sharding algorithms
- Well-designed application architecture
- Robust monitoring and operations
Key Takeaway: Sharding should be a last resort after exhausting simpler scaling strategies. When you do shard, plan carefully and design for operational simplicity.
Next Steps
Database Replication
Learn about replication strategies before considering sharding
CAP Theorem
Understand trade-offs in distributed databases
Choosing a Database
Select the right database that scales for your needs
Database Performance
Optimize before scaling