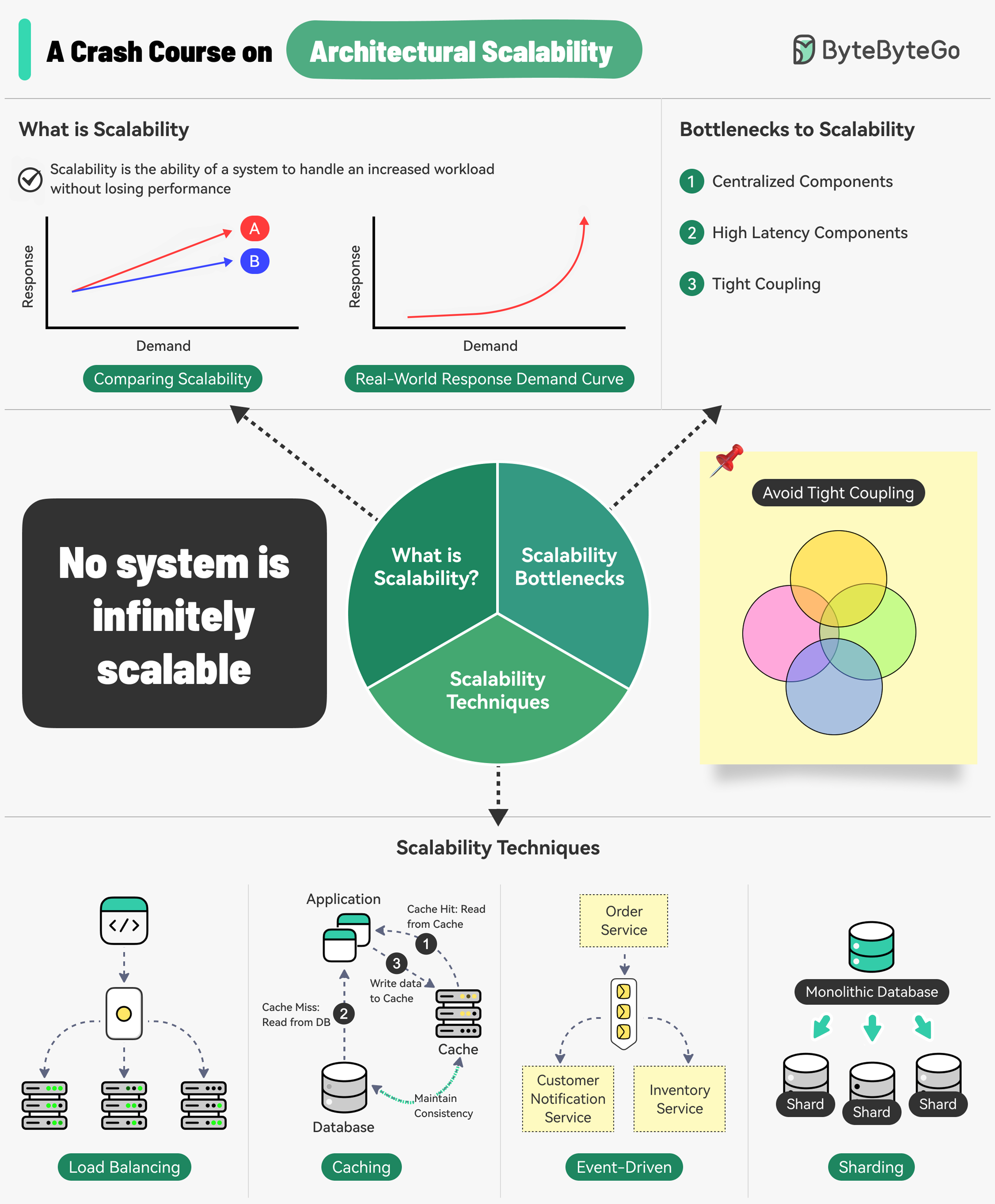
Introduction Scalability is the ability of a system to handle an increased workload without losing performance. However, we can also look at scalability in terms of the scaling strategy - the system’s ability to handle an increased workload by repeatedly applying a cost-effective strategy.
What do Amazon, Netflix, and Uber have in common? They are extremely good at scaling their system whenever needed.
Bottlenecks to Scalability Three main bottlenecks prevent systems from scaling effectively:
Centralized Components Can become a single point of failure and limit horizontal scaling
High Latency Components Components that perform time-consuming operations slow down the entire system
Tight Coupling Makes components difficult to scale independently
To build a scalable system, follow the principles of statelessness , loose coupling , and asynchronous processing .
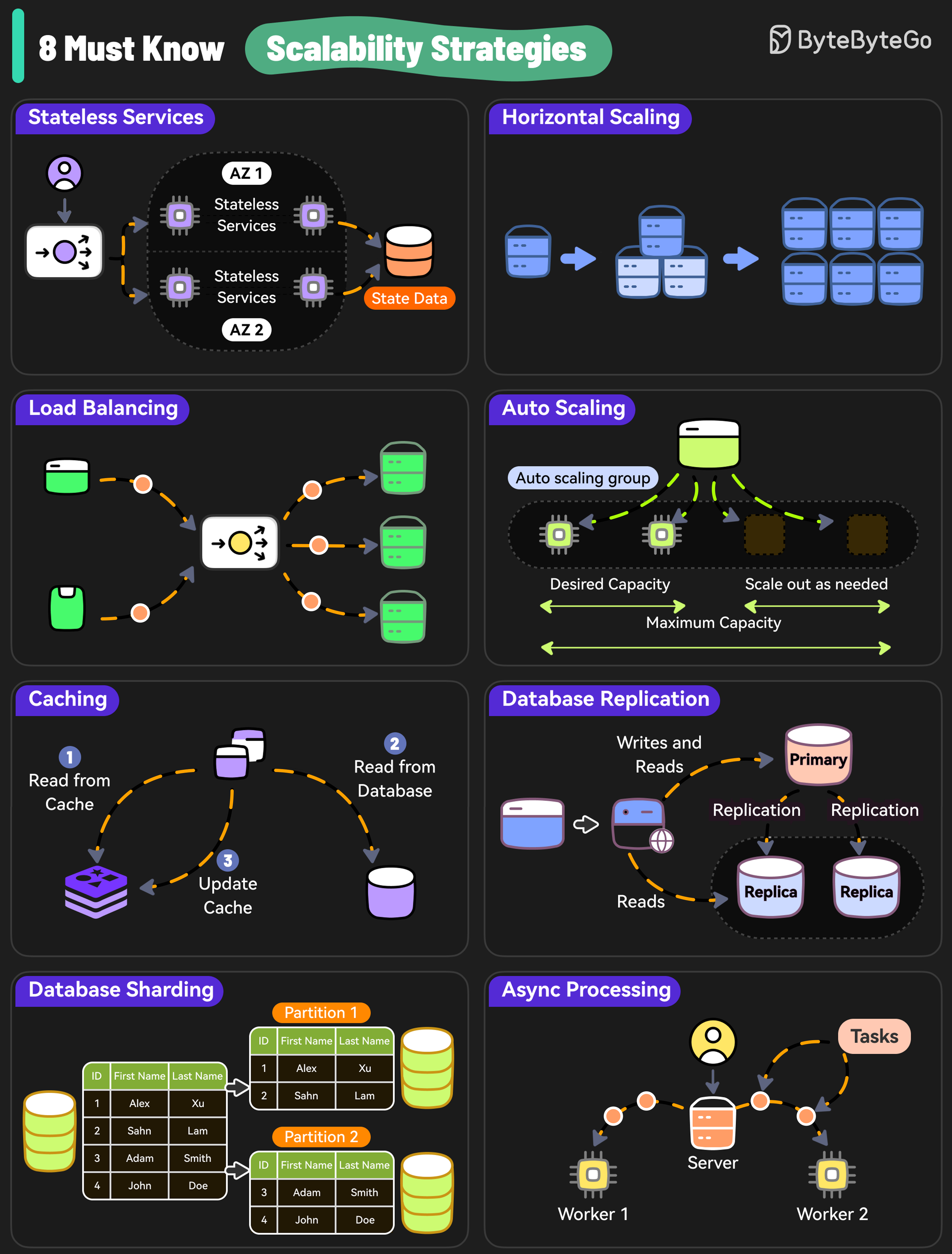
8 Must-Know Scalability Strategies 1. Stateless Services Design stateless services because they don’t rely on server-specific data and are easier to scale.
Benefits:
Any server can handle any request
Easy to add or remove servers
Simplified load balancing
Better fault tolerance
Implementation:
Store session data in external cache (Redis, Memcached)
Use JWT tokens for authentication
Design APIs to be stateless
2. Horizontal Scaling Add more servers so that the workload can be shared across multiple machines.
Advantages:
No theoretical limit to scaling
Better fault tolerance
More cost-effective at scale
Easier to implement auto-scaling
vs. Vertical Scaling:
Vertical: Add more resources (CPU, RAM) to existing server
Horizontal: Add more servers to distribute load
3. Load Balancing Use a load balancer to distribute incoming requests evenly across multiple servers.
Load Balancing Algorithms:
Round Robin : Distribute requests sequentiallyLeast Connections : Send to server with fewest active connectionsIP Hash : Route based on client IP addressWeighted Round Robin : Assign weights based on server capacity
4. Auto Scaling Implement auto-scaling policies to adjust resources based on real-time traffic.
Key Components:
Scaling Policies : Define when to scale up/downHealth Checks : Monitor instance healthMetrics : CPU, memory, request count, custom metricsCooldown Periods : Prevent rapid scaling fluctuations
Example Triggers:
CPU utilization > 70%: Add servers
Request queue length > 1000: Scale up
Average response time > 500ms: Increase capacity
5. Caching Use caching to reduce the load on the database and handle repetitive requests at scale.
Caching Layers:
CDN : Cache static content at edge locationsApplication Cache : Cache application-level data (Redis, Memcached)Database Cache : Query result cachingBrowser Cache : Client-side caching
Common Strategies:
Cache-Aside : Application loads data into cacheWrite-Through : Write to cache and database simultaneouslyWrite-Behind : Write to cache first, sync to database laterRefresh-Ahead : Proactively refresh cache before expiration
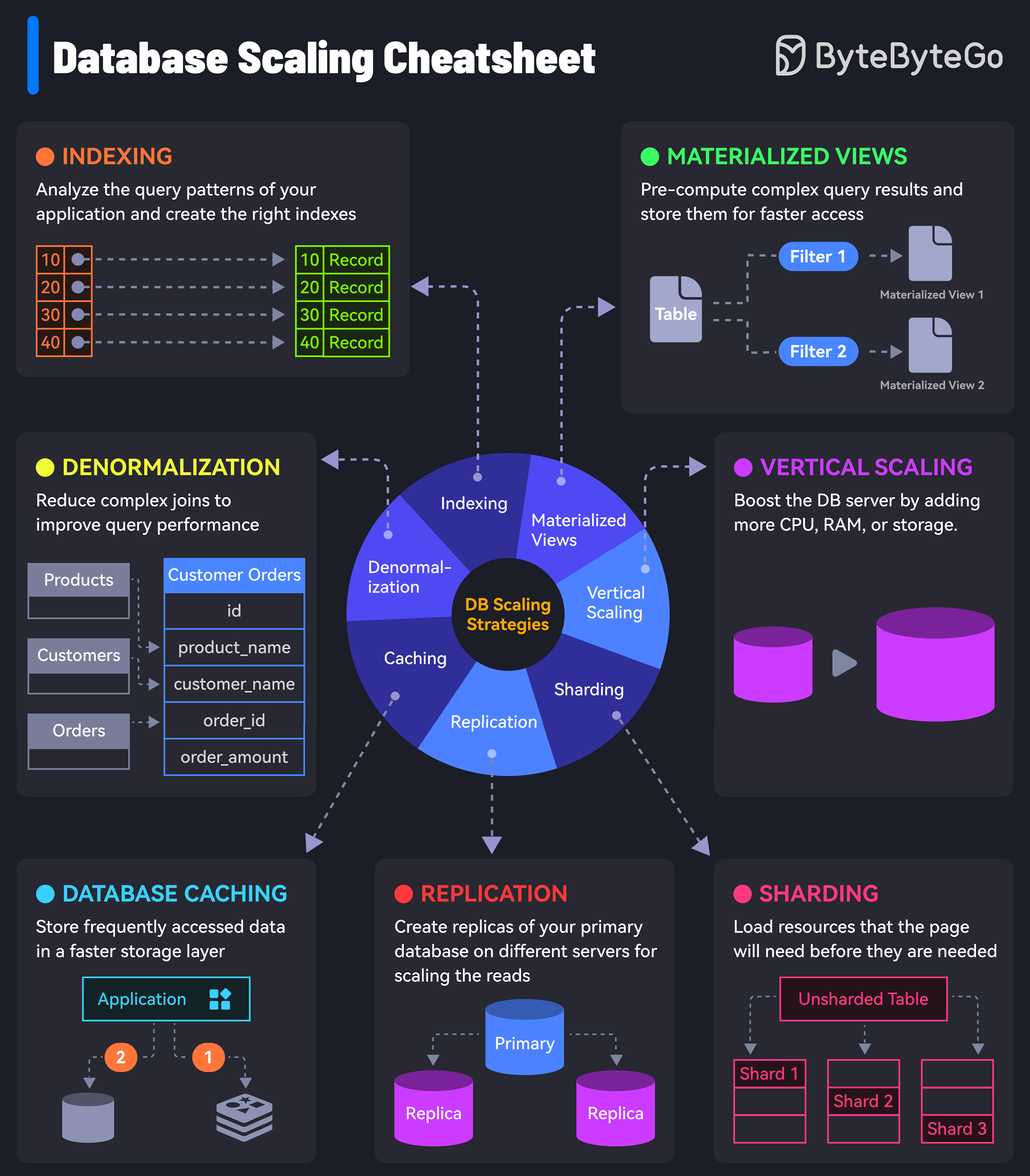
6. Database Replication Replicate data across multiple nodes to scale read operations while improving redundancy.
Replication Types: Primary-Replica
Primary-Primary
Multi-Region
Primary handles writes
Replicas handle reads
Asynchronous or synchronous replication
Easy to implement
Multiple primaries handle writes
Bidirectional replication
Higher complexity
Better write throughput
Replicas in different geographic regions
Reduces latency for global users
Disaster recovery
Higher cost
7. Database Sharding Distribute data across multiple instances to scale both writes and reads.
Sharding Strategies:
Partition data based on ranges (e.g., user IDs 1-1000, 1001-2000) Pros : Simple to implement, easy to add new rangesCons : Can lead to uneven distribution (hot shards)
Use hash function on key to determine shard Pros : Even distribution of dataCons : Difficult to add/remove shards, range queries are complex
Partition data by geographic location Pros : Low latency for regional users, data localityCons : Uneven distribution if regions have different user bases
Maintain a lookup service to determine shard location Pros : Flexible, easy to rebalanceCons : Lookup service becomes bottleneck, additional complexity
8. Async Processing Move time-consuming and resource-intensive tasks to background workers using async processing to scale out new requests.
Use Cases:
Email sending
Image/video processing
Report generation
Data import/export
Batch operations
Implementation Patterns:
Message Queues : RabbitMQ, AWS SQSEvent Streaming : Kafka, AWS KinesisTask Queues : Celery, BullServerless : AWS Lambda, Azure Functions
Scaling to Millions of Users The diagram above illustrates the evolution of a simplified eCommerce website from a monolithic design on one single server to a service-oriented/microservice architecture.
Evolution Steps
Separate Web and Database
With growth, one single application server cannot handle the traffic. Put the application server and database server on separate machines.
Deploy Server Cluster
The business continues to grow, and a single application server is no longer enough. Deploy a cluster of application servers.
Add Load Balancer
Now incoming requests need to be routed to multiple application servers. A load balancer ensures each server gets an even load.
Implement Read Replicas
With continued growth, the database might become the bottleneck. Separate reads and writes - frequent read queries go to read replicas.
Scale Database
One single database cannot handle the load. Options:
Vertical partition : Add more power (CPU, RAM)Horizontal partition : Add more database serversCaching layer : Offload read requests
Microservices Architecture
Modularize functions into different services. The architecture becomes service-oriented/microservice-based.
Database Scaling Strategies Beyond replication and sharding, there are several other strategies to scale your database:
1. Indexing Check the query patterns of your application and create the right indexes.
Best Practices:
Index columns used in WHERE clauses
Index columns used in JOIN operations
Consider composite indexes for multiple columns
Monitor index usage and remove unused indexes
2. Materialized Views Pre-compute complex query results and store them for faster access.
When to Use:
Complex aggregations
Frequently accessed reports
Data that doesn’t change often
Acceptable data staleness
3. Denormalization Reduce complex joins to improve query performance by storing redundant data.
Trade-offs:
✅ Faster reads
✅ Simpler queries
❌ More storage space
❌ Data consistency challenges
❌ More complex writes
4. Connection Pooling Reuse database connections to reduce overhead of creating new connections.
5. Query Optimization
Avoid SELECT *
Use LIMIT for pagination
Optimize JOIN operations
Use EXPLAIN to analyze queries
6. Vertical Scaling Boost your database server by adding more CPU, RAM, or storage.
Advantages:
Simple to implement
No application changes needed
Maintains data consistency
Limitations:
Hardware limits
Expensive at high scale
Single point of failure
Downtime during upgrades
Common Scalability Techniques
Load Balancing Spread requests across multiple servers to prevent a single server from becoming a bottleneck
Caching Store the most commonly requested information in memory for faster access
Event-Driven Processing Use an async processing approach to handle long-running tasks without blocking
Sharding Split a large dataset into smaller subsets (shards) for horizontal scalability
Best Practices Design for failure - Assume components will fail and build redundancy into your system.
Monitor everything - Track metrics for CPU, memory, disk I/O, network, and application-specific metrics.
Key Principles:
Start simple, scale when needed
Don’t over-engineer early
Measure before optimizing
Scale based on actual metrics
Design stateless components
Makes scaling easier
Improves fault tolerance
Simplifies deployment
Use managed services
Reduce operational overhead
Built-in scalability
Focus on business logic
Implement graceful degradation
Degrade non-critical features under load
Maintain core functionality
Better user experience
Test at scale
Load testing
Chaos engineering
Performance benchmarking
Measuring Scalability Key Metrics:
Throughput : Requests per secondLatency : Response time (p50, p95, p99)Error Rate : Failed requests percentageResource Utilization : CPU, memory, disk, networkCost per Request : Efficiency metric
Scalability Goals:
Linear scalability: 2x resources = 2x throughput
Sub-linear scalability: 2x resources = 1.5-2x throughput
Super-linear scalability: 2x resources = >2x throughput (rare)
AWS Services Learn about AWS services for scalable applications
Distributed Patterns Explore distributed system design patterns
Resilience Build resilient and fault-tolerant systems
 Load Balancing Algorithms:
Load Balancing Algorithms:
 Sharding Strategies:
Sharding Strategies:
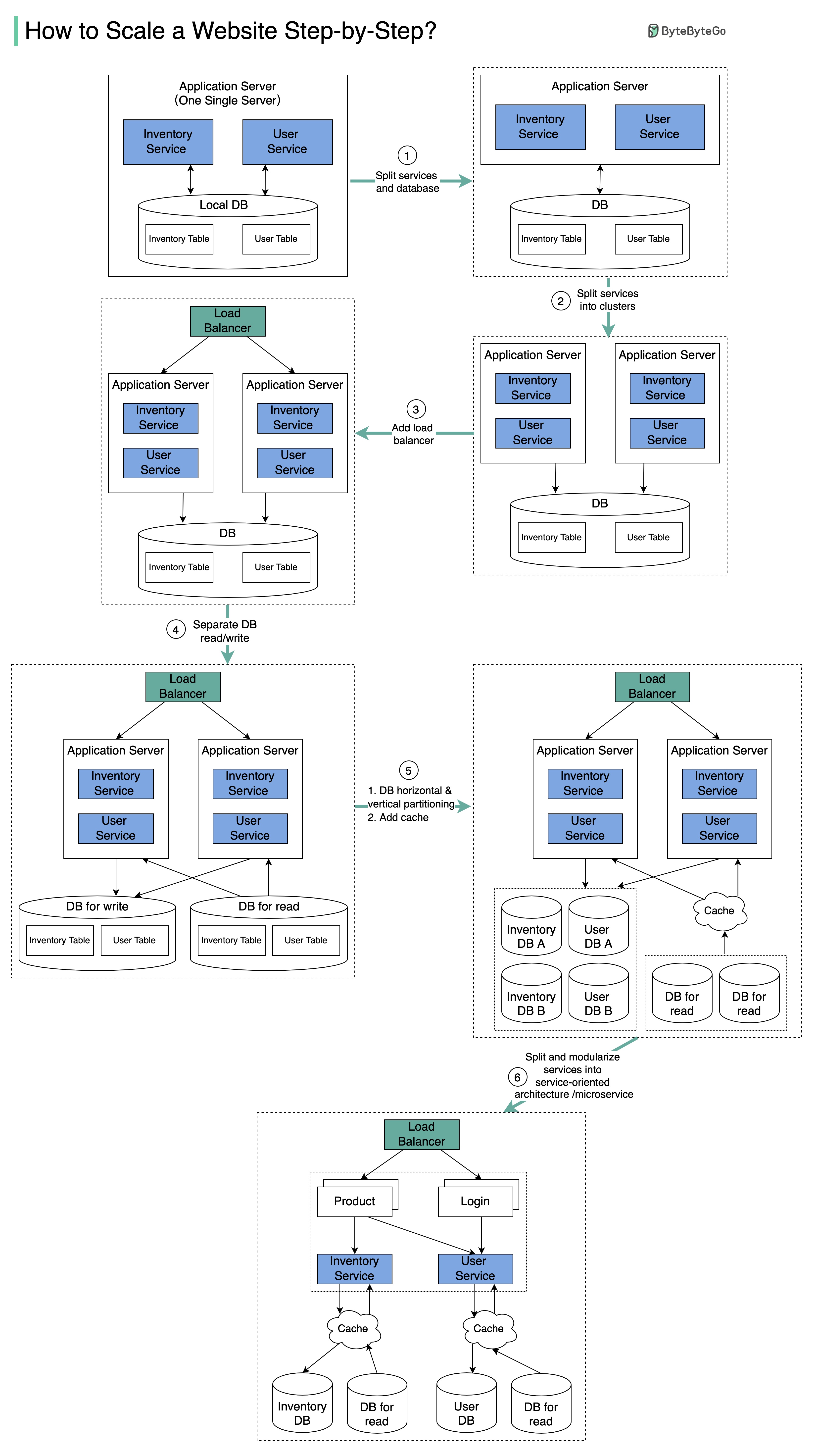 The diagram above illustrates the evolution of a simplified eCommerce website from a monolithic design on one single server to a service-oriented/microservice architecture.
The diagram above illustrates the evolution of a simplified eCommerce website from a monolithic design on one single server to a service-oriented/microservice architecture.