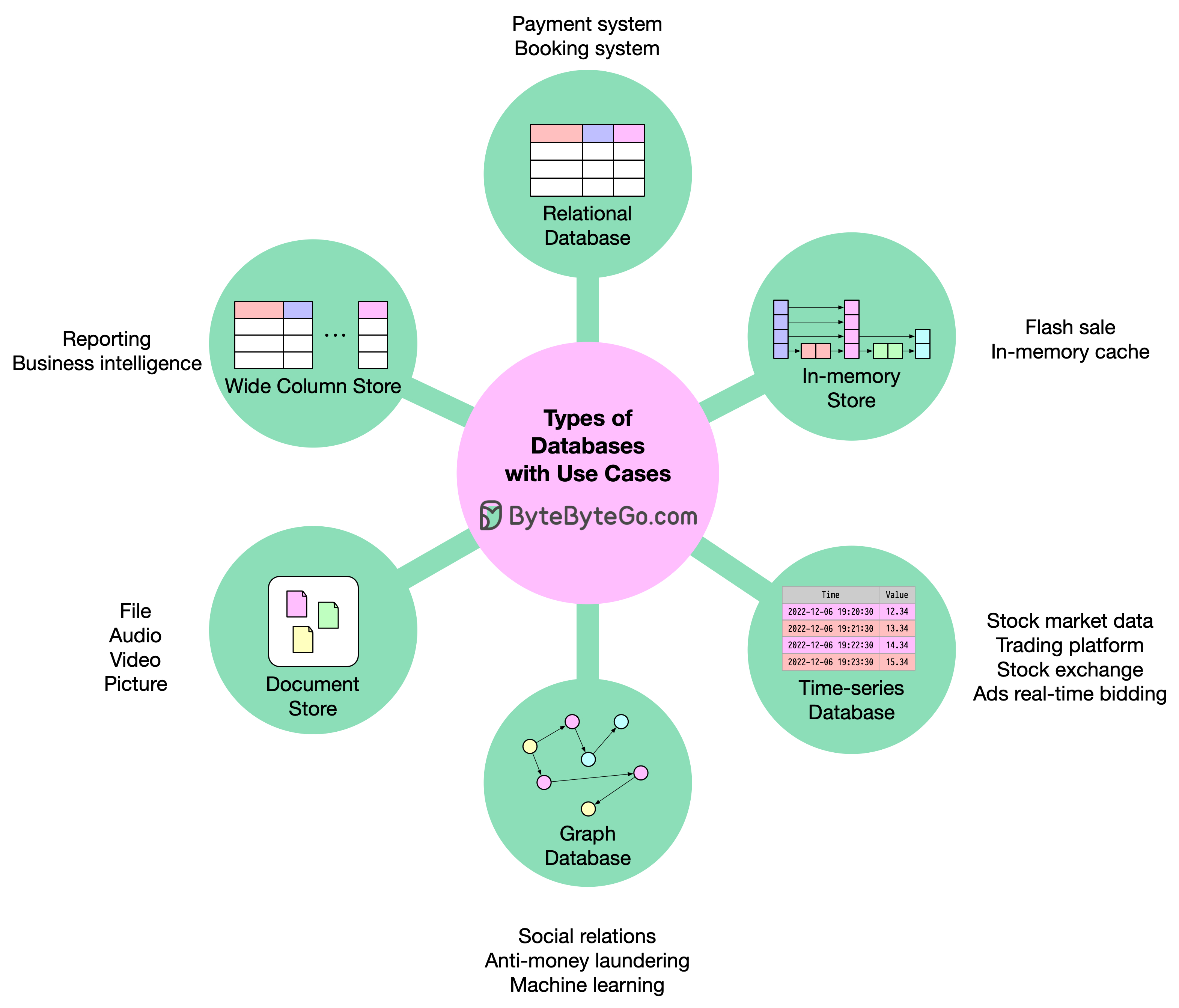
Introduction
With hundreds or even thousands of databases available today—including Oracle, MySQL, MariaDB, SQLite, PostgreSQL, Redis, ClickHouse, MongoDB, S3, and Ceph—choosing the right database for your system can be overwhelming. This guide will help you understand the different types of databases and when to use each one.Understanding Database Categories
Different types of databases excel at different tasks. The key is understanding your data access patterns, consistency requirements, and scalability needs.Relational Databases
Best for: General-purpose applications, complex queries, transactional systems Relational databases organize data in neat tables with well-defined relationships. They’re the well-behaved sibling of the database world, keeping everything in order.Strengths
- ACID compliance for data integrity
- Complex query support with SQL
- Strong consistency guarantees
- Well-established ecosystem
Use Cases
- E-commerce platforms
- Banking systems
- ERP applications
- Content management systems
In-Memory Stores
Best for: Caching, session management, real-time analytics In-memory databases store data in RAM rather than on disk, making them exceptionally fast. Their speed and limited data size make them ideal for fast operations where milliseconds matter.In-memory stores are typically 100-1000x faster than disk-based databases for read operations.
- Lightning-fast read/write operations
- Limited by available RAM
- Often used alongside persistent databases
- Support for data structures like sets, sorted sets, and hashes
Time-Series Databases
Best for: IoT data, metrics, logs, monitoring systems Time-series databases are optimized for storing and querying time-stamped data. They excel at handling continuous streams of data points indexed by time. Key Features:- Efficient storage compression for time-series data
- Built-in time-based aggregations
- High write throughput
- Automatic data retention policies
Graph Databases
Best for: Social networks, recommendation engines, fraud detection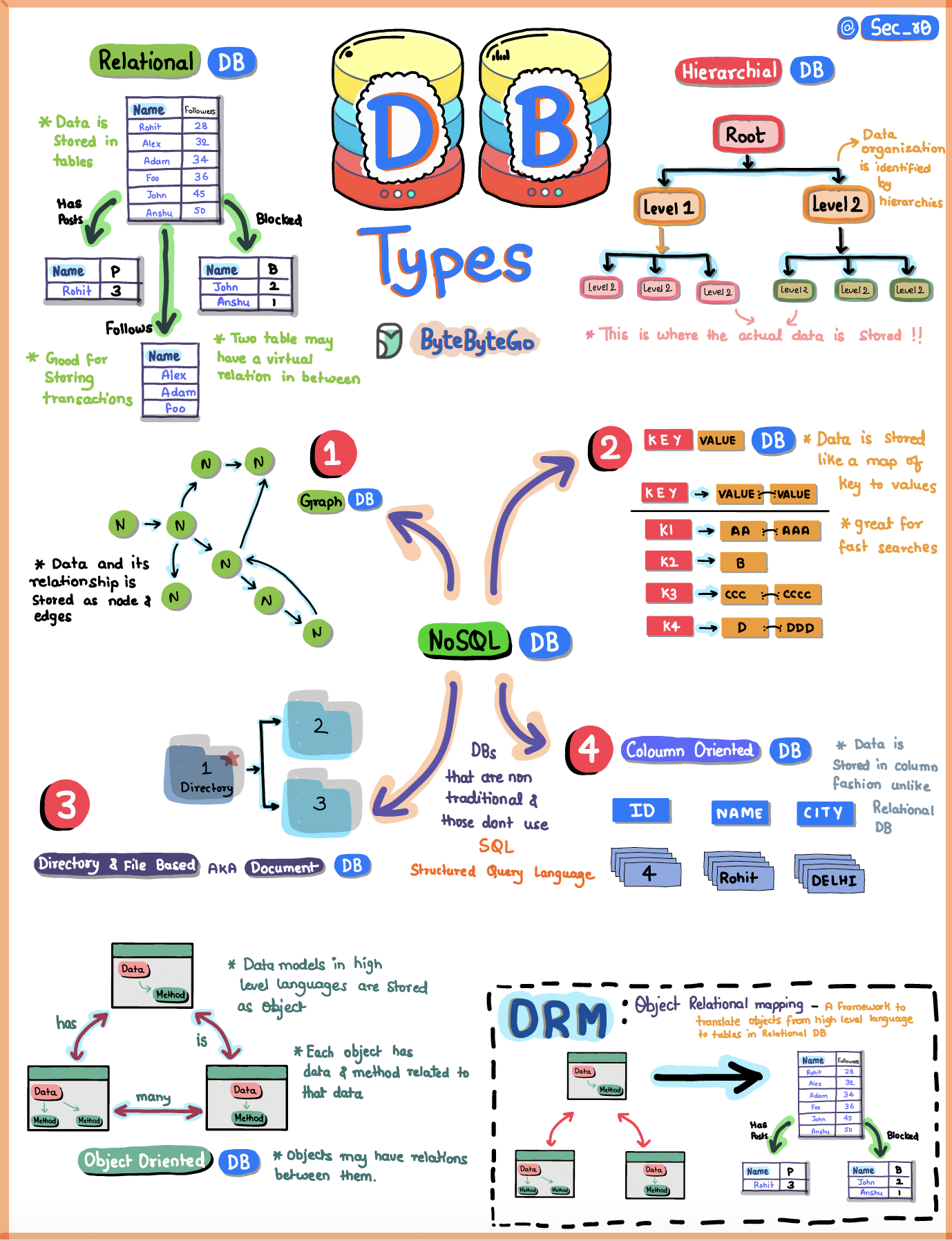 Graph databases are suitable for complex relationships between unstructured objects. They excel when the relationships between data points are as important as the data itself.
Key Characteristics:
Graph databases are suitable for complex relationships between unstructured objects. They excel when the relationships between data points are as important as the data itself.
Key Characteristics:
- Native relationship storage
- Fast traversal of connections
- Flexible schema
- Pattern matching queries
- Social network connections (friends, followers)
- Product recommendations
- Network topology
- Knowledge graphs
Document Stores
Best for: Content management, catalogs, user profiles Document databases store information in a format similar to JSON. They’re designed for working with documents instead of tables, making them ideal for large amounts of immutable or semi-structured data. Key Features:- Schema flexibility
- Nested data structures
- Fast read operations
- Horizontal scalability
Wide Column Stores
Best for: Big data analytics, reporting, data warehousing Wide column stores are designed for big data, analytics, and reporting scenarios that need denormalized data. They organize data by columns rather than rows, making them efficient for analytical queries. Key Characteristics:- Optimized for analytical queries
- Column-based compression
- Distributed architecture
- High write throughput
OLAP Databases
Best for: Business intelligence, data warehousing, reporting Online Analytical Processing (OLAP) databases are optimized for complex analytical queries and reporting purposes. They excel at aggregating large amounts of data. Key Features:- Columnar storage for fast aggregations
- Complex query optimization
- Historical data analysis
- Batch processing capabilities
Decision Framework
When choosing a database, consider these key factors:Analyze Your Data Model
Is your data highly structured with fixed schemas, or does it vary significantly?
Understand Access Patterns
Will you primarily read or write? Do you need real-time access or batch processing?
Consider Consistency Requirements
Do you need strong consistency (ACID) or can you tolerate eventual consistency?
Common Patterns
Many modern applications use multiple databases for different purposes:- PostgreSQL for transactional data
- Redis for caching and session storage
- Elasticsearch for full-text search
- S3 for blob storage
- InfluxDB for time-series metrics
Next Steps
SQL vs NoSQL
Understand the differences between SQL and NoSQL databases
Database Sharding
Learn how to scale your database horizontally
Replication Patterns
Explore database replication strategies
CAP Theorem
Understand trade-offs in distributed databases