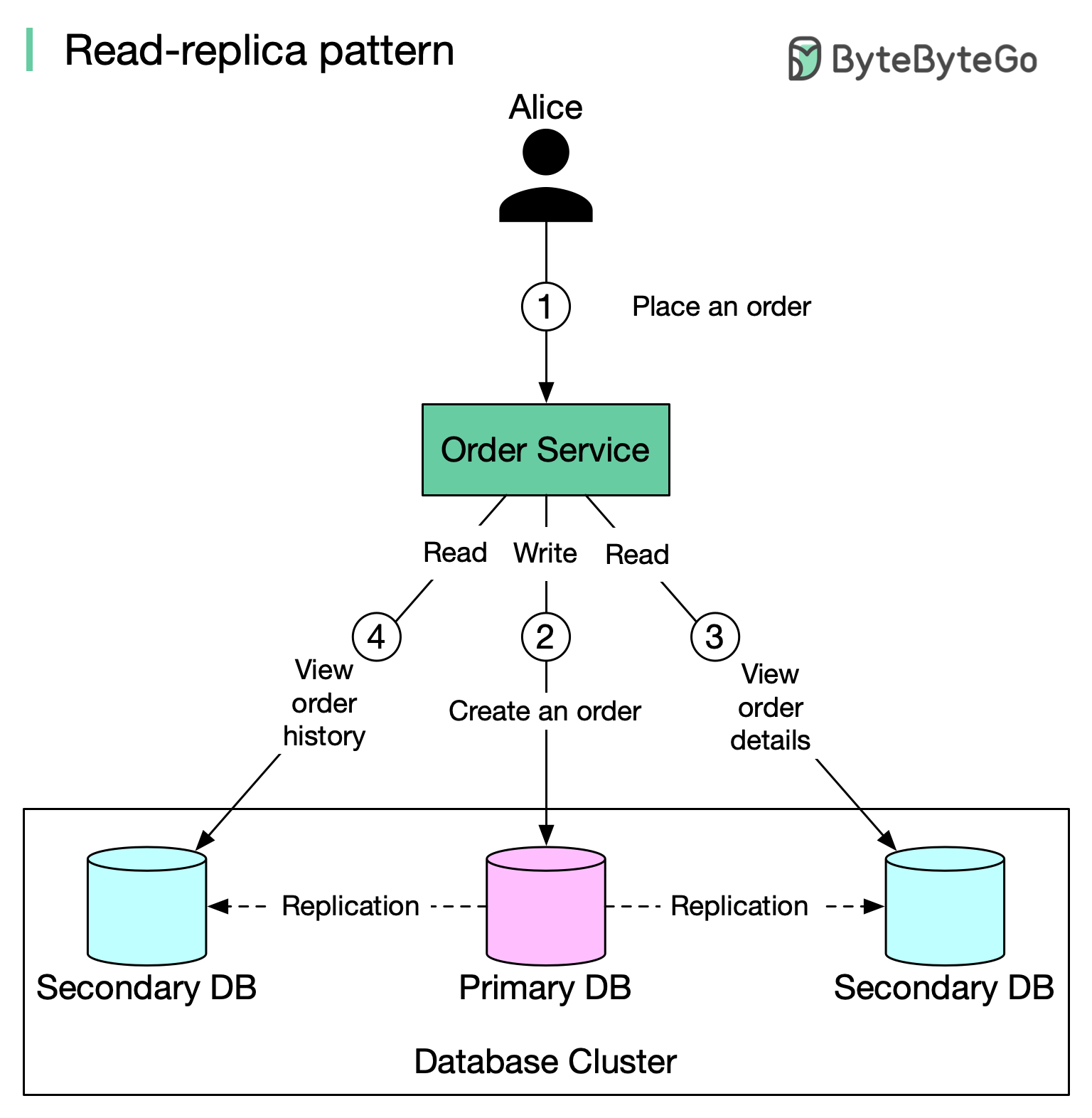
What is Database Replication?
Database replication is the process of creating and maintaining multiple copies of a database across different servers. It’s a fundamental technique for:Scaling Reads
Distribute read traffic across multiple database servers
High Availability
Maintain service even if the primary database fails
Geographic Distribution
Place data closer to users for lower latency
The Read Replica Pattern
The most common replication setup is the read replica pattern, where:- All write operations (INSERT, UPDATE, DELETE) go to the primary database
- Read operations (SELECT) are distributed across read replicas
How It Works
The diagram above illustrates a typical read replica setup:Write to Primary
When Alice places an order on Amazon, the Order Service creates a record in the primary database.
Replication Strategies
Master-Slave (Primary-Replica) Replication
The most common pattern with one primary and multiple replicas.Characteristics
Characteristics
Write Path:
- All writes go to primary (master)
- Primary applies changes locally
- Changes are propagated to replicas
- Reads can be served from any replica
- Load balanced across replicas
- Primary can also serve reads
- Simple to understand and implement
- Excellent for read-heavy workloads
- Clear data source of truth (primary)
- Single point of failure for writes
- Replication lag can cause consistency issues
- Manual failover often required
- E-commerce platforms (many product views, fewer purchases)
- Content management systems
- Analytics dashboards
- Any read-heavy application
Master-Master (Multi-Master) Replication
Multiple databases can accept writes simultaneously.Characteristics
Characteristics
Write Path:
- Writes can go to any master
- Changes propagate to other masters
- Conflict resolution required
- Reads from any master
- Typically lower latency
- No single point of failure for writes
- Better write performance and availability
- Geographic distribution of writes
- Complex conflict resolution
- Risk of data inconsistency
- Harder to reason about
- Network partitions are challenging
- Multi-region applications requiring local writes
- High-availability systems that can’t tolerate write downtime
- Collaborative applications with offline support
Chain Replication
Replicas form a chain where each replicates from the previous one.- Reduces load on primary
- Better for many replicas
- Higher latency to final replica
- Failure in chain disrupts replication
Implementation Approaches
Application-Level Routing
The application code decides which database to use for each query.Pros and Cons
Pros and Cons
Advantages:
- Full control over routing logic
- Can implement custom strategies
- No additional infrastructure
- Complexity in application code
- Every service must implement routing
- Harder to change strategy
- Potential for bugs in routing logic
Database Middleware
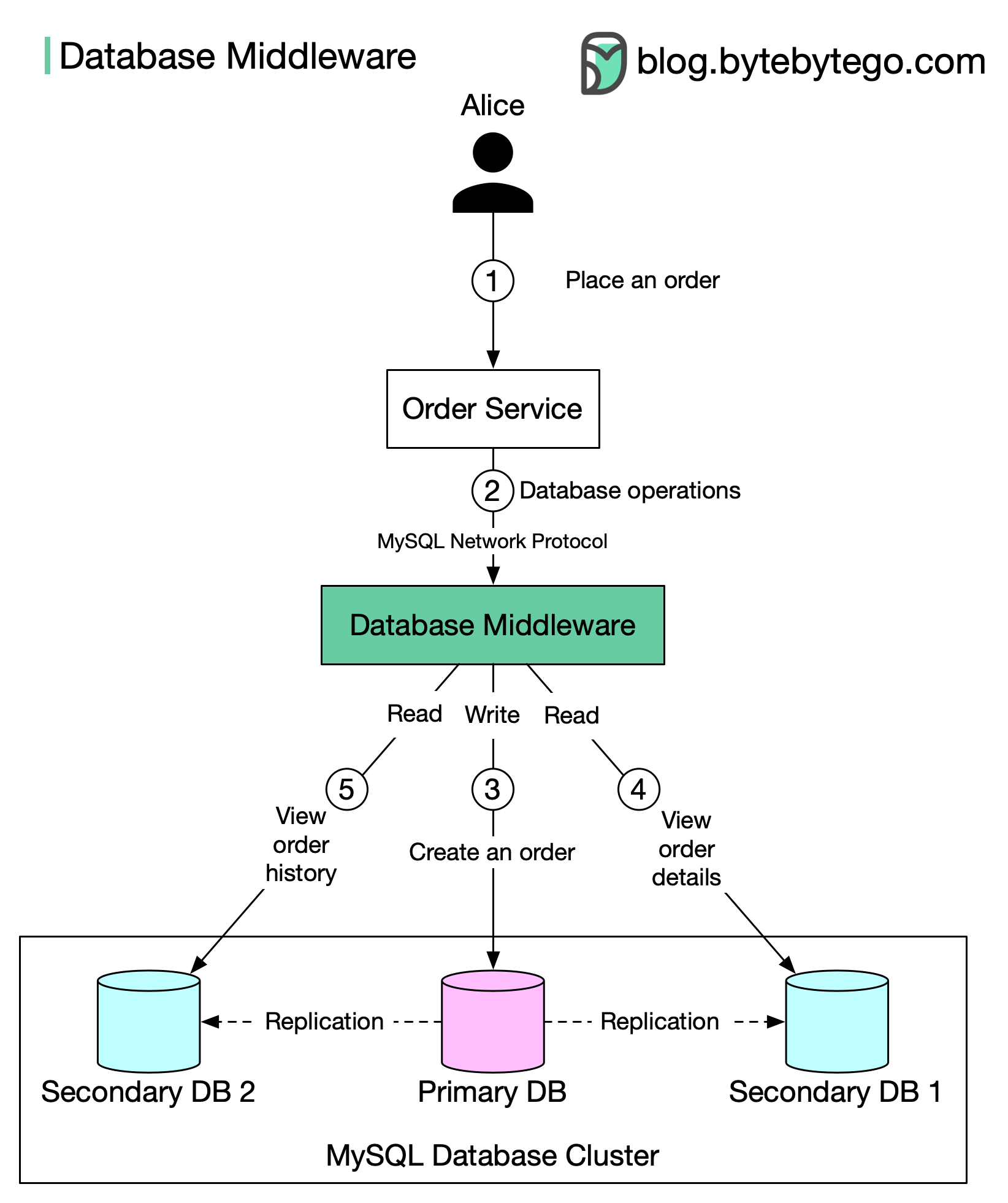 A middleware layer sits between the application and databases, handling routing transparently.
How it works:
A middleware layer sits between the application and databases, handling routing transparently.
How it works:
Application Connects to Middleware
The application connects to the middleware as if it’s a regular database.
Middleware Routes Queries
The middleware analyzes each query and routes it appropriately:
- Writes → Primary database
- Reads → Replica databases (load balanced)
Pros and Cons
Pros and Cons
Advantages:
- Simplified application code
- Centralized routing logic
- Better compatibility (uses standard MySQL protocol)
- Easier database migration
- Can implement sophisticated routing rules
- Additional network hop increases latency
- Requires high availability setup (can be single point of failure)
- Complex middleware system to maintain
- Must handle connection pooling, authentication, etc.
- ProxySQL (MySQL/MariaDB)
- PgBouncer (PostgreSQL)
- HAProxy with MySQL
- MaxScale (MariaDB)
- Vitess (MySQL)
The middleware uses standard database protocols (e.g., MySQL network protocol), so any compatible client can connect without modification.
Replication Mechanisms
Synchronous Replication
Writes are confirmed only after replicas acknowledge receipt.- Strong consistency
- Higher latency (wait for replicas)
- Guaranteed data durability
- Lower throughput
Asynchronous Replication
Writes are confirmed immediately; replication happens in the background.- Lower latency
- Higher throughput
- Risk of data loss if primary fails
- Eventual consistency
Semi-Synchronous Replication
A hybrid approach where at least one replica acknowledges before confirming the write.- Balanced latency and durability
- Reduced data loss risk
- Good compromise for most applications
The Replication Lag Problem
The Problem Illustrated
Consider Alice’s order from the earlier example:- Alice places an order → Writes to primary ✓
- Data begins replicating to replicas…
- Alice immediately checks order status → Reads from replica
- Replica hasn’t received the update yet → Order not found! ❌
Read-After-Write Consistency
This scenario requires read-after-write consistency: users should always see their own writes immediately.Solutions to Replication Lag
1. Route to Primary for Latency-Sensitive Reads
2. Time-Based Routing
3. Check Replication Status
Many databases provide ways to check if a replica is caught up:4. Session Affinity (Sticky Sessions)
Route all requests from a session to the same database:5. Monotonic Reads
Ensure users don’t see data “go backwards in time”:Scaling Database Strategies
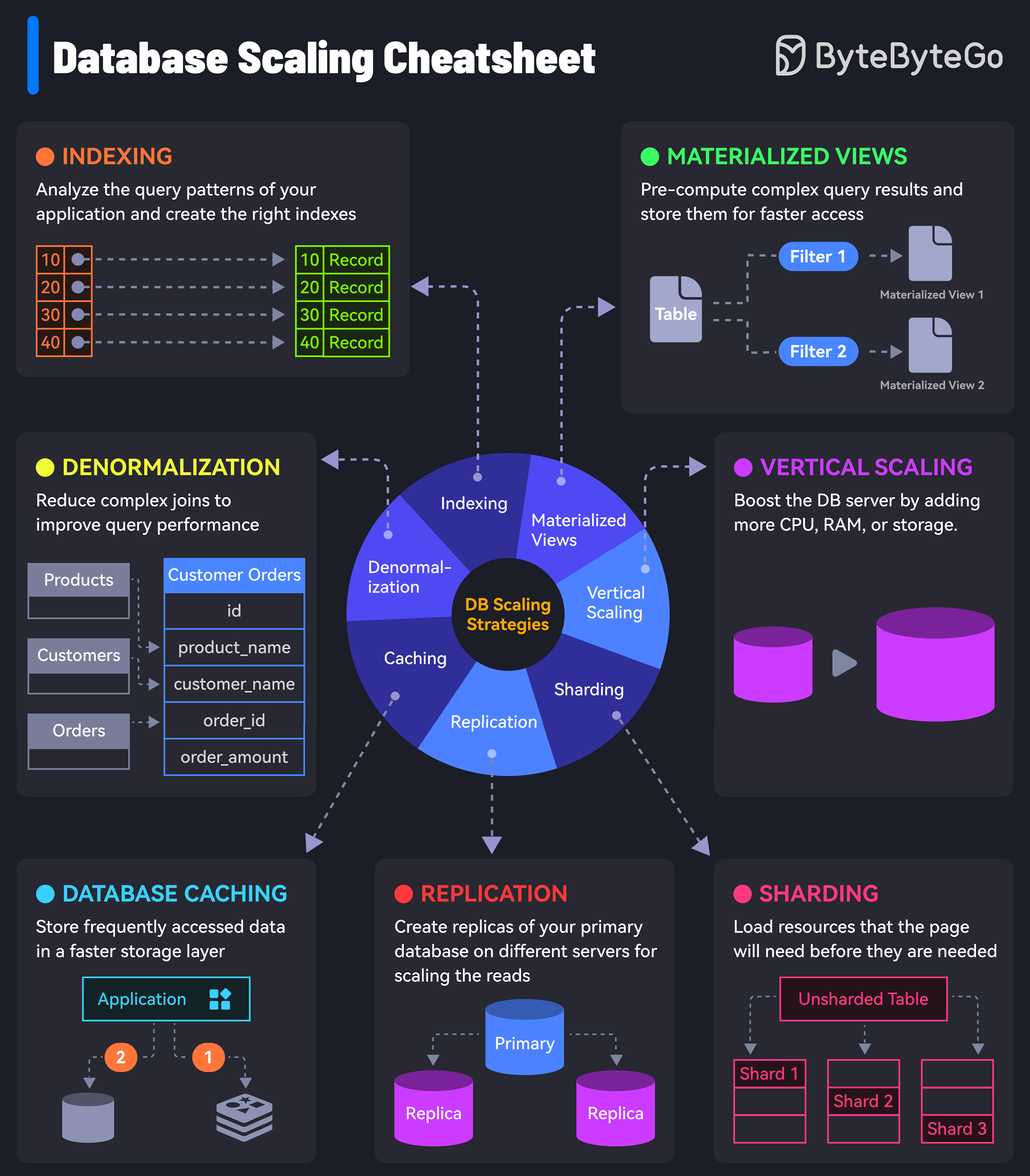 Replication is one of several scaling strategies:
Replication is one of several scaling strategies:
Replication scales reads. For write-heavy workloads, consider sharding or caching strategies.
Best Practices
1. Monitor Replication Lag
- Replication lag (seconds behind)
- Replication throughput
- Failed replication attempts
- Replica health checks
2. Plan for Failover
What happens when the primary fails?
Automation options:
- MySQL: MHA (Master High Availability), Orchestrator
- PostgreSQL: Patroni, repmgr
- Cloud: AWS RDS Multi-AZ, Google Cloud SQL HA
3. Load Balance Replicas
Distribute read traffic evenly:4. Geographic Distribution
Place replicas near users:5. Consider Read-Only Replicas
Enforce read-only mode on replicas:Common Pitfalls
When to Use Replication
Implement replication when:Read traffic significantly exceeds write traffic
You need high availability for reads
Users are geographically distributed
Analytics queries are impacting production performance
You need to perform backups without impacting primary
- Can caching solve your problem more simply?
- Is your database properly indexed?
- Can you optimize expensive queries?
- Do you have connection pooling configured?
Conclusion
Database replication is a proven strategy for scaling read traffic and improving availability. The key to success is:- Choose the right replication strategy for your consistency needs
- Handle replication lag appropriately in your application
- Monitor continuously and set up alerts
- Plan for failover before you need it
- Test regularly to ensure your replication setup works as expected
Next Steps
Database Sharding
Scale writes with horizontal partitioning
CAP Theorem
Understand consistency vs availability trade-offs
High Availability
Design systems that stay up during failures
Caching Strategies
Reduce database load with effective caching